I am currently working on developing services to ensure compatibility of Gladys 4 with my setup. Having already implemented voice recognition in v3 with Snips, I am considering improving my Snips assistant and developing a service based on it.
I am therefore opening this topic so that we can discuss this service, find out what you would like to see with it, the possibilities that such a service brings, and possibly collect a certain number of example sentences that will be used to train the assistant.
Hello
I am very interested in this service
I will be looking for:
an evolving assistant (doesn’t matter the sentence, it will understand the purpose).
a secret keeper (all locally).
Just out of curiosity, how do you plan to use snips since its acquisition by sonos we talk about it here?
for info rhasspy seems to be the future of snips open source ^^.
Absolutely! I installed and tested it. Quite pleased with the result. The community seems quite small at the moment but the people seem very active.
I will do a quick overview with screenshots as soon as I have a moment.
I discovered your link, I didn’t know about it.
The downside is that you have to associate it with a Raspberry Pi. And between buying the Pi and the matrix voice, you might as well go straight for a Respeaker.
I have a Respeaker V2 6 mics.
Rhasspy speech-to-text works well.
On the other hand, have you tested text-to-speech? Is there a way to have a good voice without going through Google Voice?
Hello @Biscotte,
If you want to test Rhasspy in standalone mode and for French, and if you know a bit about Docker, I have put the docker-compose file here.
It includes Rhasspy + MaryTTS (which allows you to have other voices). Both have a web interface to test and configure them. I test on a Debian VM on my Windows machine to use my PC’s headset.
Unfortunately, I don’t use Rhasspy with Gladys, so I don’t think there’s much interest in a tutorial for me.
Currently, there is no link between Rhasspy and Gladys.
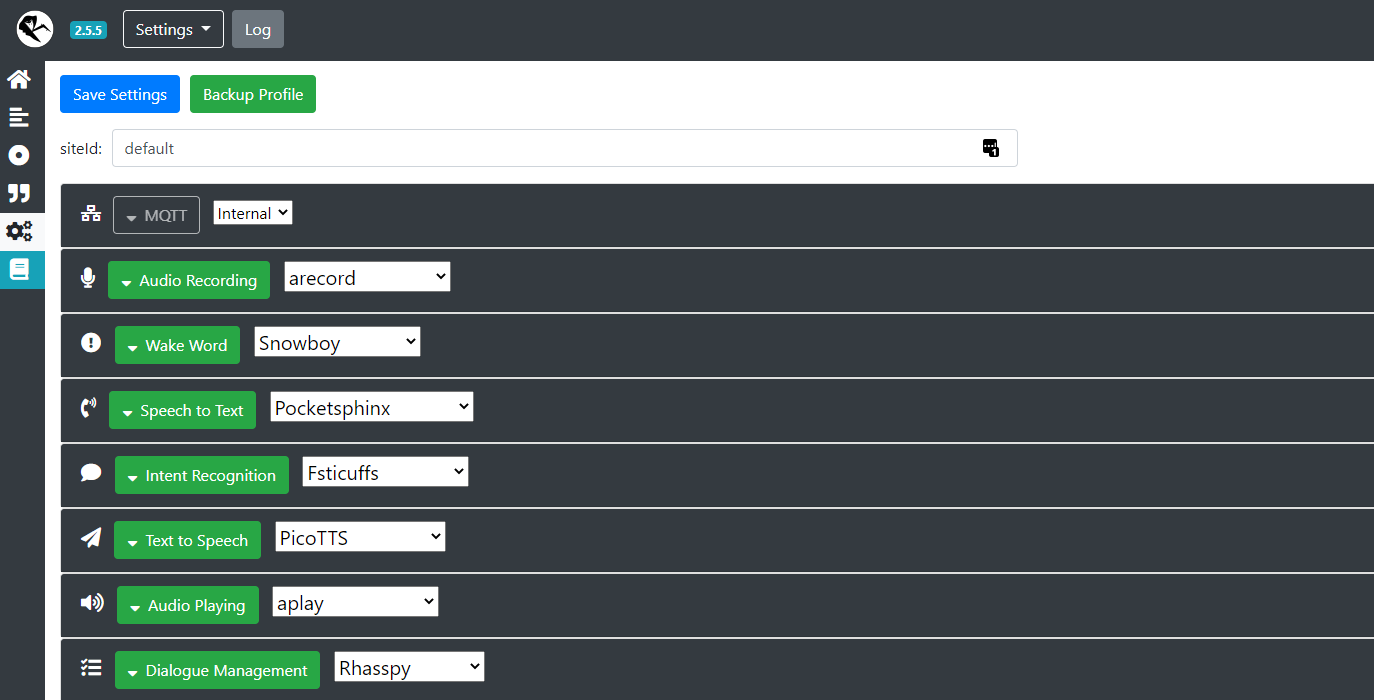
For Rhasspy, you just need to deploy a container and then go to the web interface to configure it. I had put in this same thread the configuration I have for the wake word, TTS, and so on. I can take a screenshot if you want.
After doing some tests, it’s very easy to retrieve Rhasspy events on Gladys. Basically, I can easily retrieve all user requests. So, this part will be easy for me to implement.
The most complicated part will be the Docker part to deploy Rhasspy correctly on all machines.
I see that in the code, it is necessary to have a user so that gladys can respond to that user when a message is sent.
The problem I have is that I don’t want a user because I don’t know who spoke into the microphone. So I can’t associate an ID. Especially since the response will be verbal. So I do receive Gladys’s return message, but it gives an error because I set the id to null.
Can we consider modifying the current route or do we need to create a new one more specific to this use case?