@cicoub13 J’arrive à reproduire ton “Maximum Call Stack” en essayant de chunk un tableau de 150k valeurs de capteurs :o ça veut dire que tu as un capteur qui a envoyé plus de 150k valeurs aha, on avait pas eu ce cas même chez @Terdious, intéressant
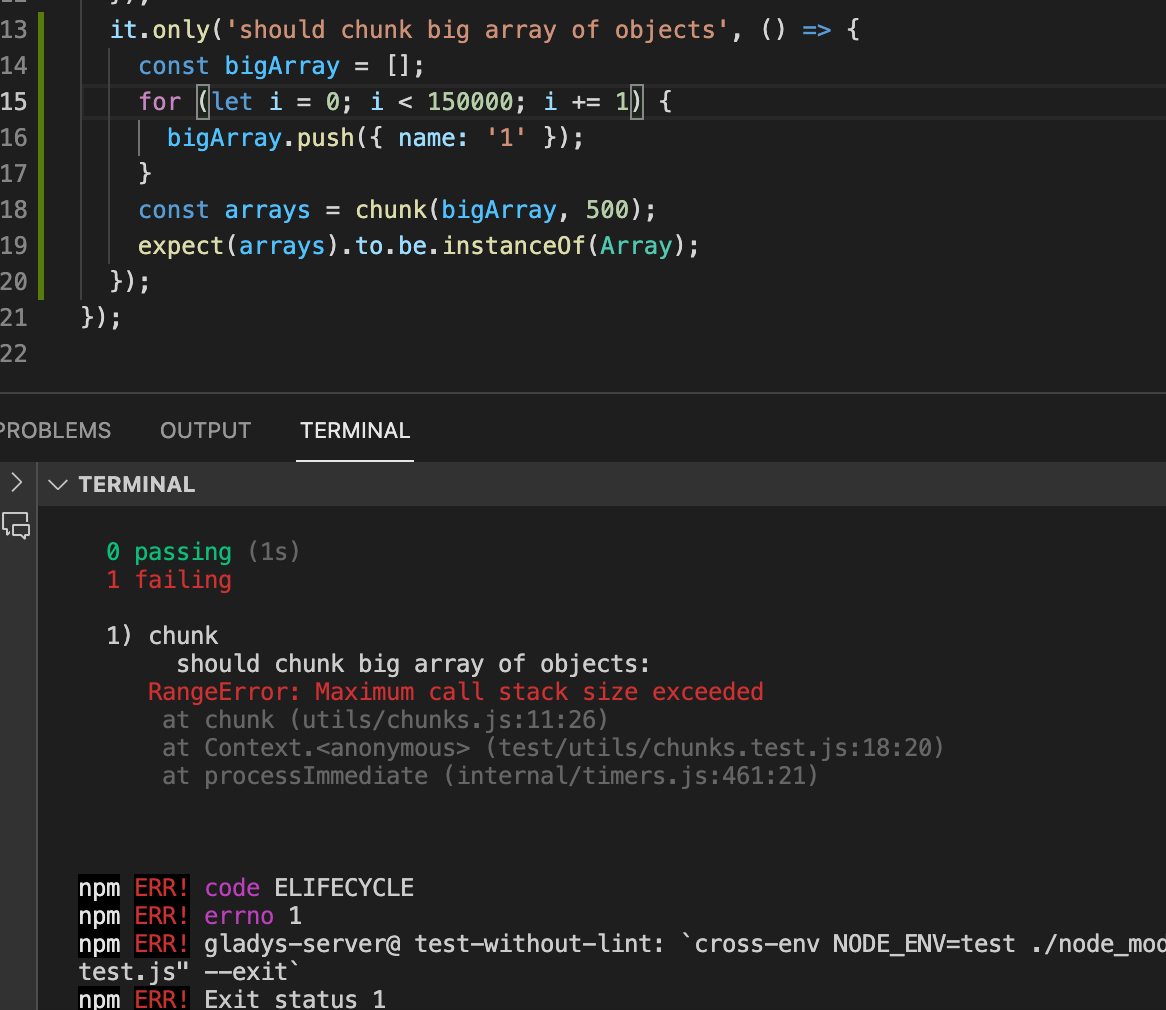
Bon j’ai trouvé une implémentation plus performante que celle qu’on a actuellement, et qui utilise “slice” au lieu de “splice”, ce qui permet de ne pas avoir à cloner le tableau avant car le tableau n’est pas muté.
Je me suis basé sur ça:
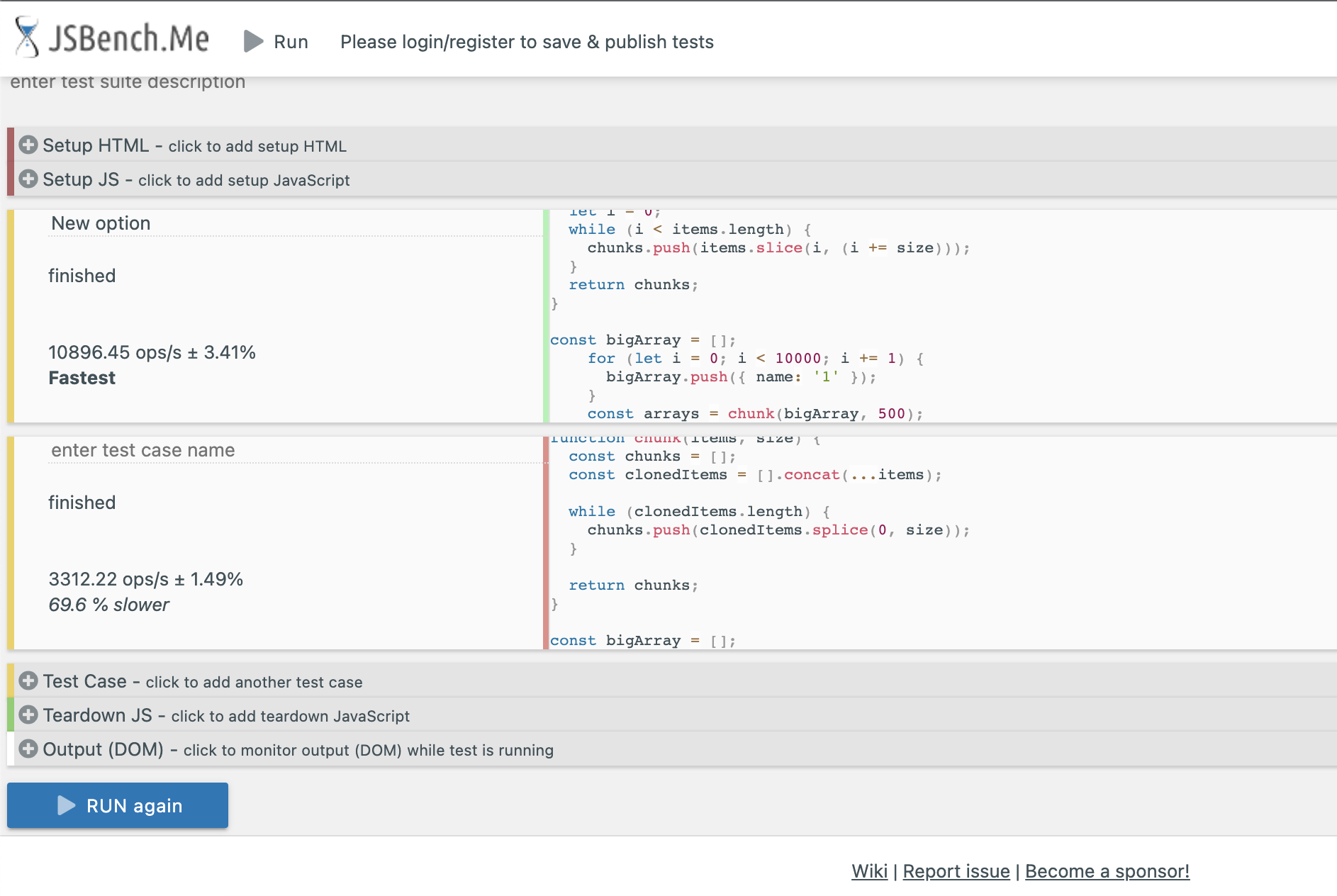
Un test de performance confirme que l’ancienne implémentation est 69.6% plus lente que la nouvelle, et surtout la nouvelle n’a pas le problème de la Maximum Call stack vu que le tableau n’est pas cloné.
Hop la PR est là pour ceux que ça intéresse:
J’ai mergé la PR et j’ai lancé un build sur le tag “dev” pour qu’on voit si ça règle bien le problème chez toi @cicoub13  ( sur Docker ça sera dispo sur
( sur Docker ça sera dispo sur gladysassistant/gladys:dev comme d’habitude)
Le build est là:
Ca prendra une heure environ
792K deviceFeatureState
5 features à 124K enregistrements - Ils sont tous liés à une prise connectée ![]() (c’est ce modèle TuYa TS0121_plug control via MQTT | Zigbee2MQTT)
(c’est ce modèle TuYa TS0121_plug control via MQTT | Zigbee2MQTT)
5 features à 15K enregistrements - Liés à un détecteur de mouvement (qui mesure aussi la lumière)
Le nombre d’enregistrements par jour est assez régulier et je n’ai que 3 mois glissants sauvegardés.
Je teste ça aujourd’hui
Voici ce que retourne l’API pour ce problème :
[{"id":"c5bac8c2-5a49-4f7c-9ad8-0e367b427df8","type":"hourly-device-state-aggregate","status":"failed","progress":52,"data":{"error_type":"purged-when-restarted"},"created_at":"2021-10-28 09:14:48.379 +00:00","updated_at":"2021-10-29 06:03:07.825 +00:00"},{"id":"83bca935-43d3-4177-ba38-e51a16c36ff6","type":"monthly-device-state-aggregate","status":"success","progress":97,"data":{},"created_at":"2021-10-28 09:04:14.845 +00:00","updated_at":"2021-10-28 09:04:16.830 +00:00"},{"id":"6f15c4b3-5acb-4747-88b3-730af6fdecc4","type":"daily-device-state-aggregate","status":"success","progress":97,"data":{},"created_at":"2021-10-28 09:04:12.809 +00:00","updated_at":"2021-10-28 09:04:14.837 +00:00"},{"id":"2e0b5f3e-bf82-4a8c-a4c5-d601a209a10b","type":"hourly-device-state-aggregate","status":"failed","progress":52,"data":{"error_type":"unknown-error","error":"Error: RangeError: Maximum call stack size exceeded\n at chunk (/src/server/utils/chunks.js:11:26)\n at /src/server/lib/device/device.calculcateAggregateChildProcess.js:147:22\n"},"created_at":"2021-10-28 09:03:22.151 +00:00","updated_at":"2021-10-28 09:04:12.802 +00:00"}]
Est-ce qu’il faudrait modifier l’intégration Zigbee2Mqtt pour ne pas enregistrer la valeur si elle n’a pas changé ? Ce serait dommage, car on peut perdre de l’information (la non variation est une information)
Tu as pu tester au final? ![]()
Très bizarre, ça parait bon !
Je ne pense pas, effectivement c’est important de garder les valeurs mêmes non changées.
En revanche, ce qu’il est possible de faire, c’est d’afficher dans l’UI l’attribut « keep_history » de chaque feature (sous forme d’un toggle), pour éventuellement permettre à l’utilisateur de ne pas enregistrer l’historique de certains appareils trop verbose/et où l’historique ne les intéressent pas:
Oui mais l’aggrégation reste bloquée à 52% (ensuite, je perds la main sur mon RPI 3B+).
Le CPU est à 100% et la RAM pleine. Et ça ne finit jamais.
J’ai essayé en supprimant les états des 2 périphériques verbeux (dont je ne me sers pas pour les graphiques) et ça marche. Je pense que tu peux laisser ton optimisation dans master.
Il va vraiment falloir que j’investisse dans un RPI4 et un SSD ![]()
Merci en tout cas pour l’investigation et la correction ![]()
J’ai créé une issue pour garder l’option keep_history Zigbee2Mqtt - Add option keep_history when adding device · Issue #1344 · GladysAssistant/Gladys · GitHub
Ah merde, effectivement si tu as 1Go de RAM et qu’une partie est déjà prise par d’autres choses, si Gladys tente de charger en RAM 130k valeurs de capteurs + tenter d’aggréger ces données heure par heure, ça peut surcharger la RAM et du coup ça n’aboutit jamais…
Dans l’UI, tu as une erreur clair quand c’est un problème de RAM ?
Ok tant mieux! Sinon, tu peux aussi dire à Gladys de ne garder que les 3 derniers mois de valeurs de capteurs dans les paramètres ![]()
Non, ça n’aboutit jamais et pas d’erreur.
Je vais faire ça en attendant le développement qui permettra de ne pas enregistrer les valeurs pour ces deux périphériques.
Sinon si c’est trop bloquant change le keep history en db
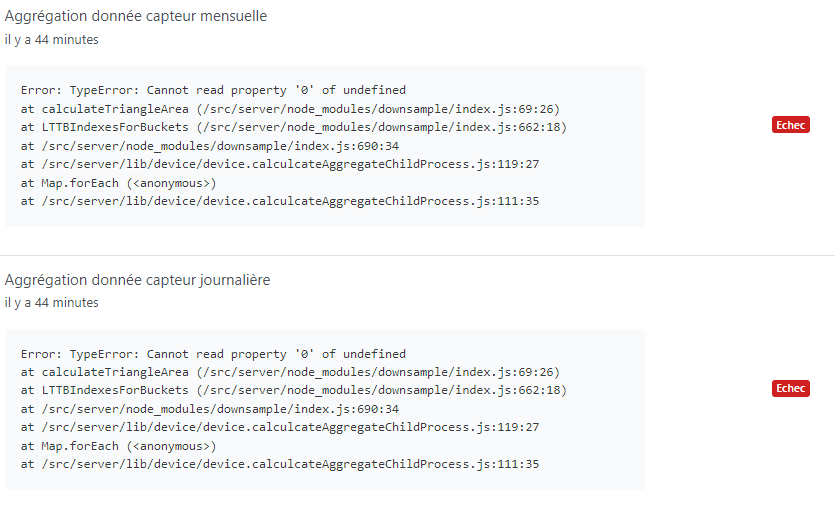
J’ai redémarré Gladys pour voir, et j’ai toujours les mêmes erreurs :
2021-11-25T12:46:18+0100 <warn> device.calculateAggregate.js:95 (Socket.<anonymous>) device.calculateAggregate stderr: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
2021-11-25T12:46:18+0100 <warn> device.calculateAggregate.js:101 (ChildProcess.<anonymous>) device.calculateAggregate: Exiting child process with code 1
2021-11-25T12:46:18+0100 <error> device.onHourlyDeviceAggregateEvent.js:22 (DeviceManager.onHourlyDeviceAggregateEvent) Error: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
at ChildProcess.<anonymous> (/src/server/lib/device/device.calculateAggregate.js:102:23)
at ChildProcess.emit (events.js:400:28)
at maybeClose (internal/child_process.js:1058:16)
at Process.ChildProcess._handle.onexit (internal/child_process.js:293:5)
2021-11-25T12:46:18+0100 <info> device.calculateAggregate.js:38 (DeviceManager.calculateAggregate) Calculating aggregates device feature state for interval daily
2021-11-25T12:46:58+0100 <warn> device.calculateAggregate.js:95 (Socket.<anonymous>) device.calculateAggregate stderr: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
2021-11-25T12:46:58+0100 <warn> device.calculateAggregate.js:101 (ChildProcess.<anonymous>) device.calculateAggregate: Exiting child process with code 1
2021-11-25T12:46:58+0100 <error> device.onHourlyDeviceAggregateEvent.js:27 (DeviceManager.onHourlyDeviceAggregateEvent) Error: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
at ChildProcess.<anonymous> (/src/server/lib/device/device.calculateAggregate.js:102:23)
at ChildProcess.emit (events.js:400:28)
at maybeClose (internal/child_process.js:1058:16)
at Process.ChildProcess._handle.onexit (internal/child_process.js:293:5)
2021-11-25T12:46:58+0100 <info> device.calculateAggregate.js:38 (DeviceManager.calculateAggregate) Calculating aggregates device feature state for interval monthly
Si ça peut aider à investiguer, je peux t’envoyer ma DB ou faire des analyses particulières.
@lmilcent J’avoue que j’avais complètement zappé ce bug! Je n’arrive pas à le reproduire chez moi, au vu de tes logs ça ressemble à un jeu de donnée particulier qui fait crasher la lib de downsampling qu’on utilise (downsample sur npm)
Est-ce que tu pourrais créer une issue GitHub sur le repo Gladys (sinon dans 10 minutes j’ai oublié  ), et m’envoyer une DB où il y a le problème effectivement (ça serait le top pour débugger )
), et m’envoyer une DB où il y a le problème effectivement (ça serait le top pour débugger )
Merci !
@lmilcent Merci! J’ai édité le titre de l’issue. (le bug NaN c’est un autre bug, rien à voir )
Même erreur de mon côté, concernant l’agrégation, pour ma part ça semble provenir des données issus des cryptos (le Shiba) qui est toujours en dessous de 0, je me demande si ça ne vient pas du nombre de décimal prise en compte dans le calcul qu’utilise la bibliothèque pour faire son aggrégation :
Cela fonctionne sur la dernière heure car je récupère les infos toutes le 5 minutes (donc surement pas d’agreg) mais pas sur la journée ou le mois.
Merci pour ton message @Albenss , je pense que certaines agrégations ont pu planter à cause d’un cas similaire.
Par exemple mon device mqtt pour gérer la présence recevait “present” avant de recevoir “1” maintenant.
Mais ça fait plusieurs mois que j’ai fait le changement déjà, et toujours des échecs.
D’une manière générale, l’erreur devrait être plus précise 
@lmilcent Je viens de regarder ta base de donnée que tu m’as envoyé, et je suis très surpris de son contenu 
Tu as des device_feature_state dont la value est “NaN” (Not a Number). C’est super étrange que ce se soit inséré d’ailleurs, vu que le champs est un “double precision”, et “NaN” n’est pas un double precision…
Forcément, ça fait crasher l’aggrégation qui attend des valeurs numériques, pas un string.

Après enquête, ces valeurs proviennent de l’intégration Zigbee2mqtt.
J’ai créé une issue GitHub pour qu’on fixe le problème:
- Rajouter une migration DB pour cleaner ces lignes qui ne devraient pas être là
- Voir pourquoi la validation et la DB ont accepté ces valeurs qui ne sont pas des Number.
En attendant, @lmilcent et @Albenss, la query SQL pour fixer vos DBs est:
DELETE FROM t_device_feature_state WHERE value = 'NaN';
@lmilcent De manière plus générale, je ne sais pas si tu tiens à toutes tes données historiques de capteurs (tu les garde toutes), mais je te conseillerais de faire un clean sur certains deviceFeatures très verbose, car actuellement pour faire l’agrégation sur mon Mac, certains capteurs contenait tellement de valeurs que ça prenait plus de 1.5 Gb de RAM pour faire l’agrégation totale (vu que comme c’est une première agrégation, ça commence du début. Ce sera pas le cas par la suite)
Sinon, en enlevant les NaN, ça marche très bien chez moi sur ta DB:
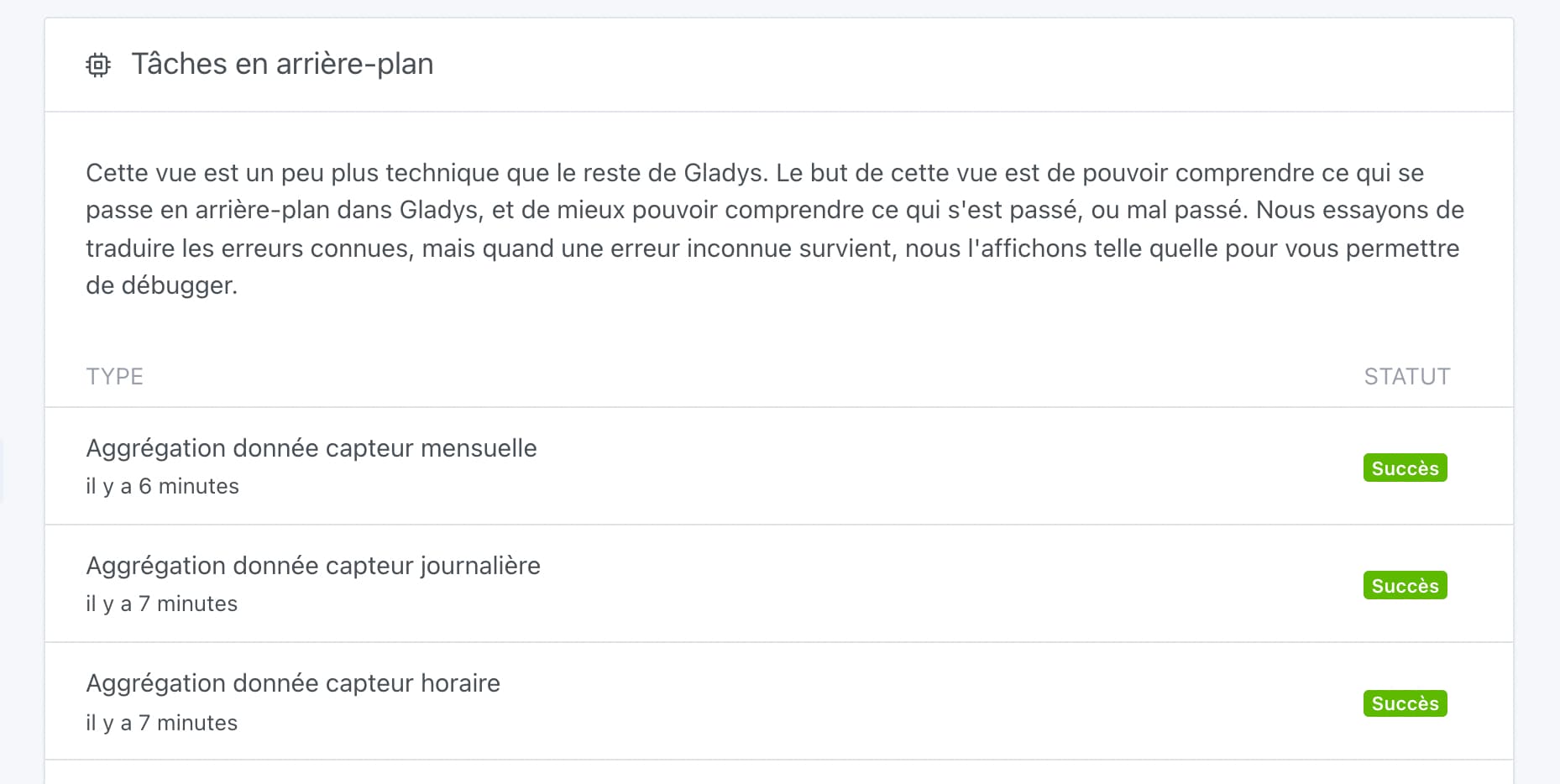
J’ai lancé la suppression des valeurs incorrectes. Je vais voir pour les autres équipements qui sont verbeux… Fonction à prévoir ? 