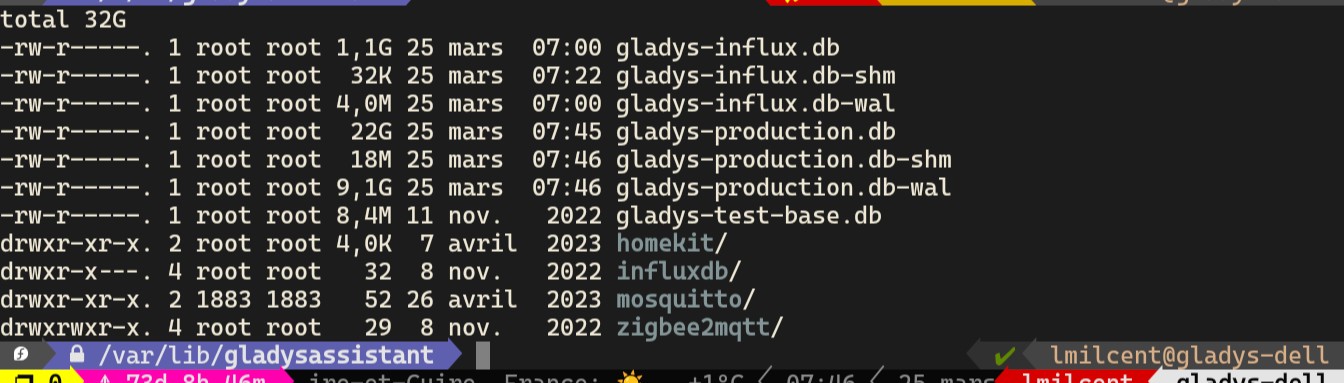
Je me retrouve avec un fichier .db-wal de presque 10Go en plus des 22 Go de la db. Je ne sais plus trop quoi faire.
Lancer la tache manuellement ne fonctionne pas, j’ai une erreur « database locked ». Même en indiquant un chemin TMPDIR différent et qui dispose de 800Go de libre.
Dans mon cas j’ai dû faire un wal_checkpoint(TRUNCATE); pour que ca vide le fichier .db-wal devenu aussi gros que la DB.
Et ensuite le VACUUM.
Gladys fait un checkpoint régulier d’habitude ?
[EDIT]
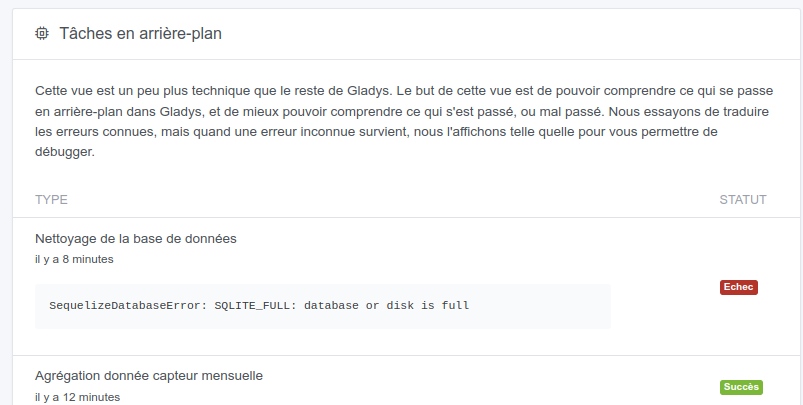
Quand Gladys lance une tâche de « Nettoyage » (donc un Vacuum), le fichier .db-wal grossi de plus en plus, jusqu’à atteindre la même taille que la db.
Je me retrouve donc avec deux énormes fichiers (tâche en cours ici) :
Ce que j’ai fait, c’est que j’ai changé la DB de place, pour une partition avec plus de place.
Mais je n’explique pas ce qui suit
Retention pas supprimée ?
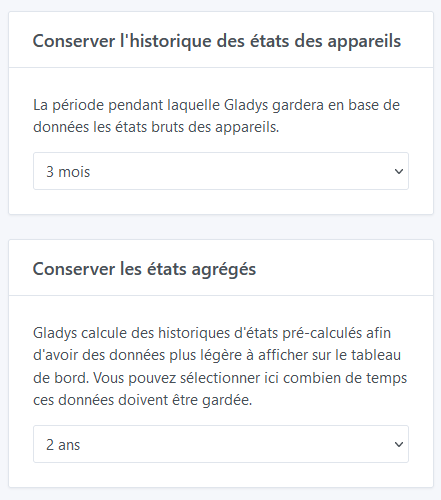
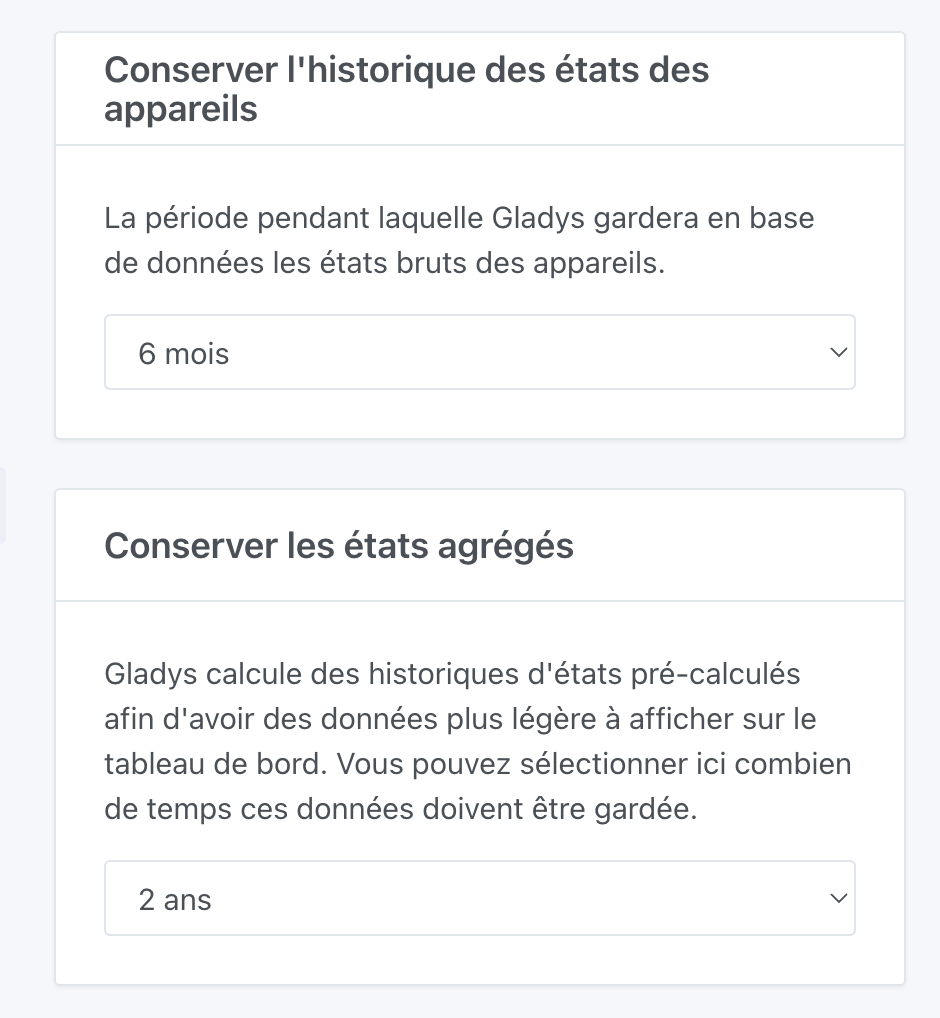
Ma DB fait 22Go, avec une rétention illimité de tous mes équipements. Pour diminuer la taille, j’ai mis en place une rétention à 6 mois des états et illimités pour les valeurs agrégées.
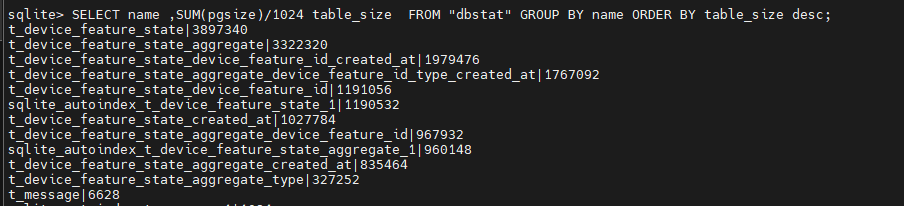
Malgré tout, même avec un VACUUM après toutes les tâches de purge de Gladys, je suis à 17Go. En cherchant, j’ai trouvé une requête pour lister le nom de valeurs par tables, et je ne comprend pas pourquoi il y a si peu de différence entre les valeurs agrégées et les valeurs brutes.
Si tu as 3 mois de rétention des états et 6 mois des états agrégés, cela veut dire que tu auras :
1 ligne pour chaque état de chaque fonctionnalité de chaque appareil pour les 3 derniers mois
1 ligne pour chaque minute (affichage heure), 1 ligne pour chaque 5 minutes (affichage jour), 1 ligne pour chaque jour (affichages semaine, mois, 3 mois, année) pour les 6 derniers mois pour chaque fonctionnalité de chaque appareil
Donc les états agrégés font quand même beaucoup de lignes
Cette commande te permet de connaître les devices/features qui enregistrent le plus d’états.
SELECT COUNT(*) as total, tdf.id, tdf.name, td.name
FROM t_device_feature_state tdfs
JOIN t_device_feature tdf ON tdf.id = tdfs.device_feature_id
JOIN t_device td ON td.id = tdf.device_id
GROUP BY device_feature_id ORDER BY total DESC;
PS: tu t’attendais à plus de réduction en ne gardant que 6 mois ?
GROUP BY device_feature_id ORDER BY total DESC;
4081384|8ede0b40-31b8-42a1-b6d8-fdfceaea35e1|Formaldehyd (Décimale)|capteurQualitéDeLair
2426183|631724ce-6fca-48c8-8588-5598f5a736ee|COV (Décimale)|capteurQualitéDeLair
2425895|b1289ec3-87f7-4dfc-bc95-80a9fa2bd840|Niveau de CO2|capteurQualitéDeLair
2000636|b0eb1e68-2b18-4c9d-b20b-0547a0641698|Intensité du signal|PriseBureau
941126|30d10a22-d247-49b9-873e-9aec623f886f|Puissance consommée|PriseBureau
785583|2c8ced8b-e581-497d-b247-e6cb884d45da|Intensité consommée|PriseBureau
611299|c1a94fd6-3413-46ef-86df-33214fb74328|Puissance consommée|PriseOnduleur
544435|4d88bc30-dbf3-4165-919d-fba0c54b728e|Intensité du signal|PriseVideoproj
512281|6f91c791-fd31-43ad-89d6-91418fffdaf1|Puissance consommée|PriseFrigoTS0121
313060|6b907ebe-c011-4dd1-af54-339b51add63f|Intensité du signal|InterrupteurSalon
302039|d9d990a1-6b0a-4d58-bc19-9a7c591ecf71|Intensité du signal|CapteurFumeeEntree
278423|3cf063a8-8ced-4134-954f-e1b81f930a16|Détection mouvement Oui/Non|CapteurMouvementEntree
En regardant de plus près, j’ai bien des état qui date de plus des 3 mois prévus. La tâche « Faire du ménage » n’est pas censé supprimer tout ça ?
Au final, en le faisant à la main, j’ai déjà probablement économisé 3.3Go si j’en crois le fichier .db-wal qui à grossi.
sqlite> DELETE FROM t_device_feature_state WHERE device_feature_id = "8ede0b40-31b8-42a1-b6d8-fdfceaea35e1" AND created_at < "2023-12-31 00:00:00.000";
J’ai 3 mois de rétention et mes derniers états sont bien du 28 Décembre.
J’ai 6 mois de rétention agrégée et mes derniers états agrégés sont bien du 27 Septembre.
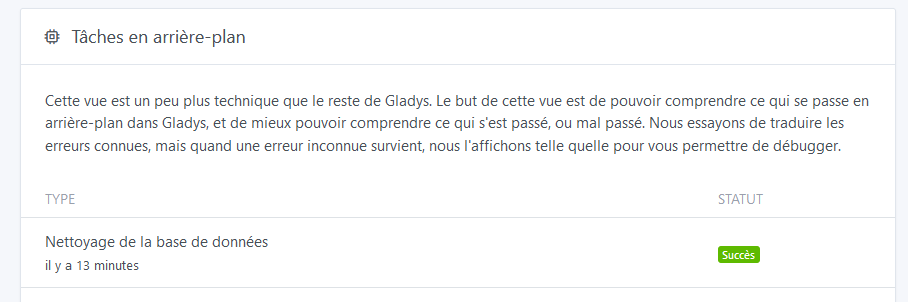
Et ta tâche Nettoyage des vieux états d'appareils est bien en Succès
Il faudrait qu’on regarde ça Write-Ahead Logging
Ça me paraît bizarre un fichier wal de plusieurs Go.
Tu ouex toujours redémarrer le docker gladys pour fermer la connexion, prendre en compte les changements et nettoyer le fichier wal.
J’ai eu un souci de partition pleine il y a quelques mois et là solution a été pour moi de… supprimer le db-wal qui était plus gros que la DB…
Radical mais je n’ai vu aucun problème par la suite…
Édit : je vois qu’en fait ton db-wal est bien supprimé donc, je suis HS. Désolé…
Je pense qu’il y a un malentendu sur la façon dont le nettoyage fonctionne dans Gladys.
Vous parlez de deux choses différentes :
Nettoyage de la base de donnée : Ce bouton n’est qu’un raccourci vers la requête SQLite VACUUM. La commande VACUUM reconstruit le fichier de base de donnée afin de libérer la place occupée par des tuples supprimés. Pour en savoir plus, la documentation de SQLite est très claire : VACUUM
Si tu changes la durée de rétention dans l’UI, le nettoyage des anciens états aura lieu au prochain 4h du matin (afin de ne pas trop déranger ta prod en journée).
Cela pourrait être affiché dans l’interface je me dis…
Du coup, si tu fais un VACUUM alors que les états sont encore là, ça ne clean rien c’est normal
Il faut attendre 4h du matin, puis faire le VACUUM
Arf, j’ai suspecté que c’était ça, mais j’étais trop pressé je pense ^^
Voyons ce matin ce que ça donne alors ! Merci d’avoir pris le temps de répondre
Je remonte ce sujet car je rencontre un problème d’espace disque faible.
Or je ne meurs pas d’envie de bidouiller ma BDD, ni d’utiliser mon terminal car j’aurai peur de tout péter (et accessoirement parce que c’est toujours très chronophage!)
Est-ce que l’un d’entre vous peut me donner une marche à suivre plus simple ? S’il en existe une ?
Met quelque chose de plus petit que ce que tu as actuellement.
Ensuite, à 4h du matin, Gladys viendra nettoyer les anciens états plus vieux que la durée choisie.
En revanche, vu que tu es arrivé à un stade assez « grave » (plus de disque du tout…), c’est possible que ça échoue, et là pas le choix tu vas devoir trouver de l’espace à la main, c’est même plus au niveau Gladys le souci, c’est au niveau système linux ^^