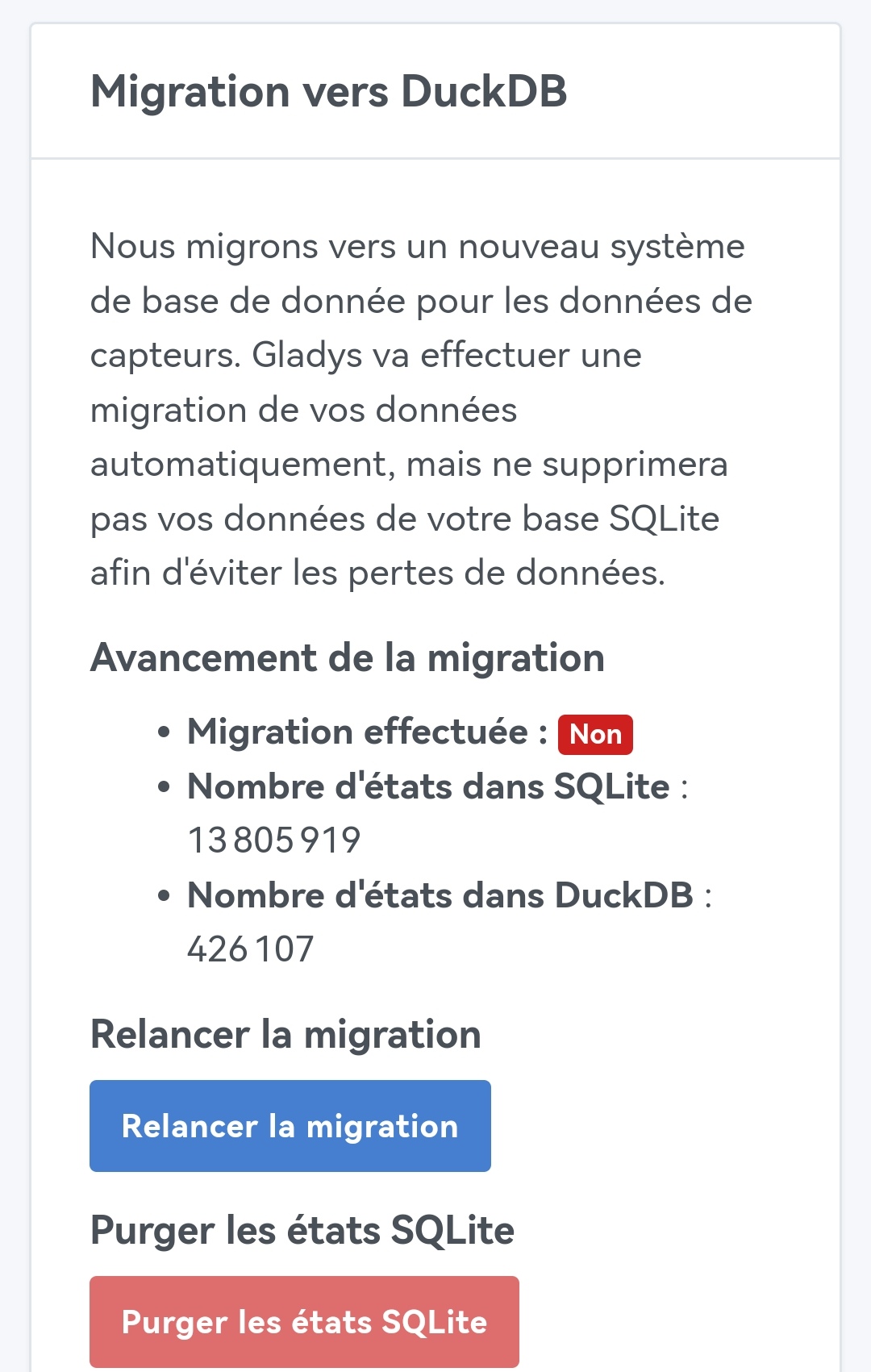
Here’s a more detailed look at how the migration went.
Overall, no problem.
First of all, I was surprised that the migration started as soon as the container was started. In itself, that doesn’t cause a problem.

However, the migration immediately started at 23%.
In the tasks, you can clearly see the progress.

It’s slow, but it’s moving forward.
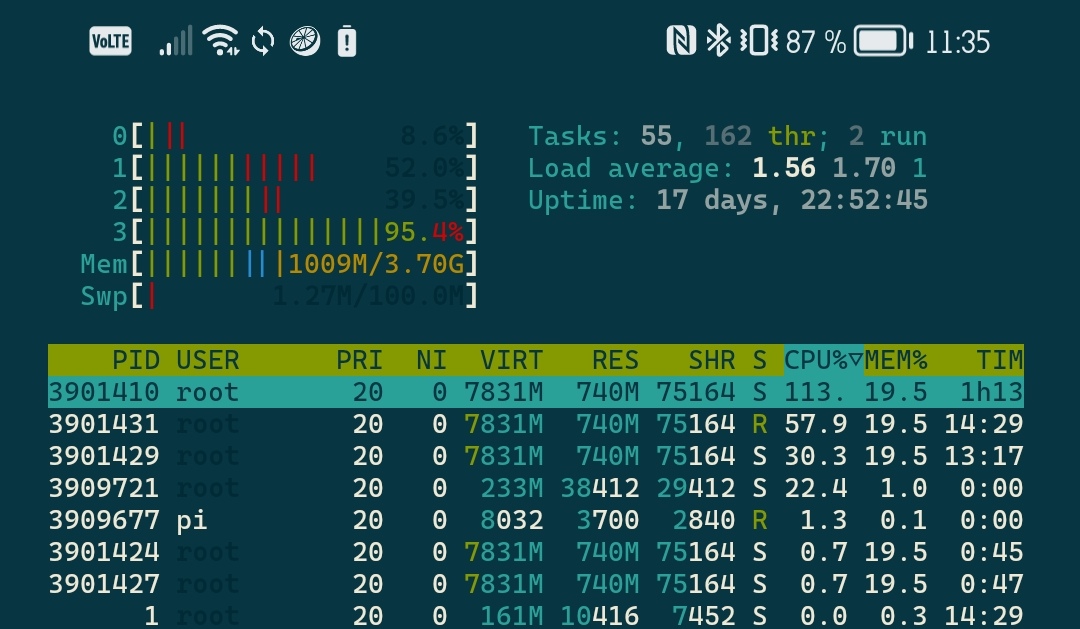
Meanwhile, Gladys is slowed but not unusable.
1GB of RAM used.
The result, crazy, a DB of 65MB instead of 11.4GB!


However, the next step, the purge… was painful!
Several very long hours during which Gladys was, on my setup, close to paralysis…
This morning, I see that
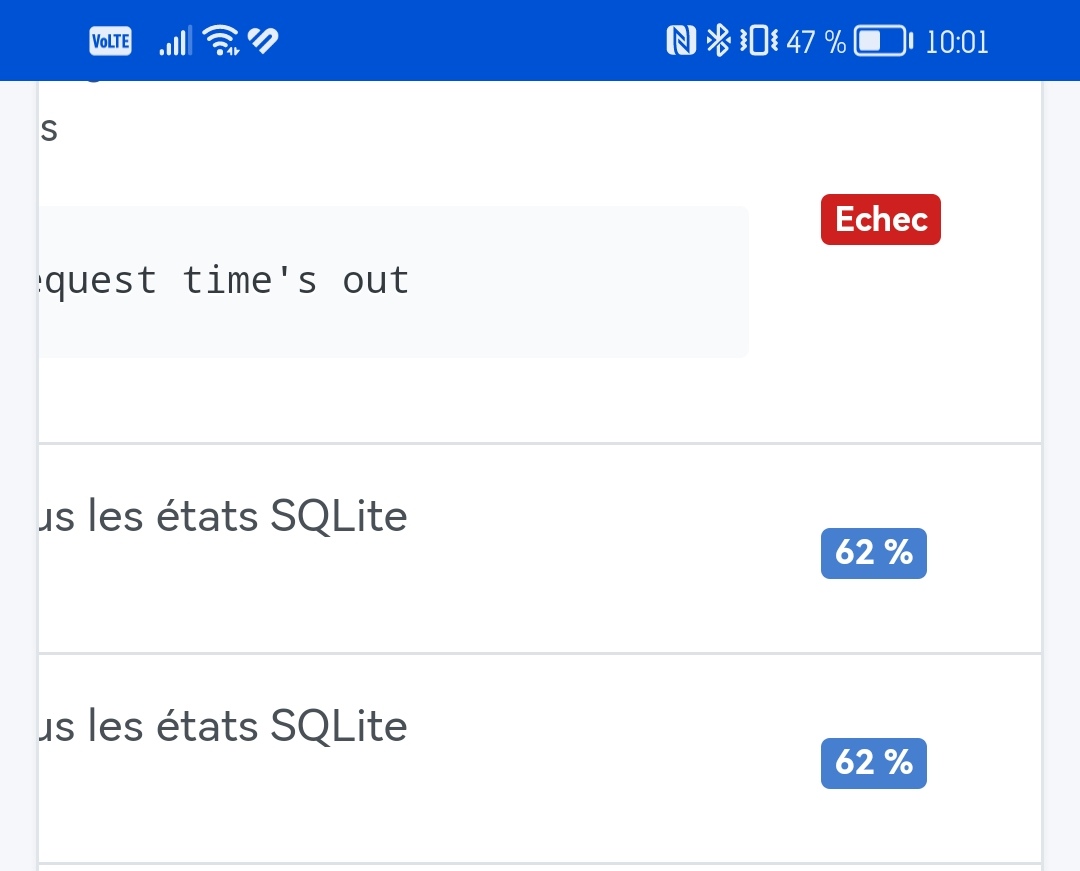
And it doesn’t move anymore.
Then I receive a restart notification for Gladys (maybe watchtower?). And in the tasks:
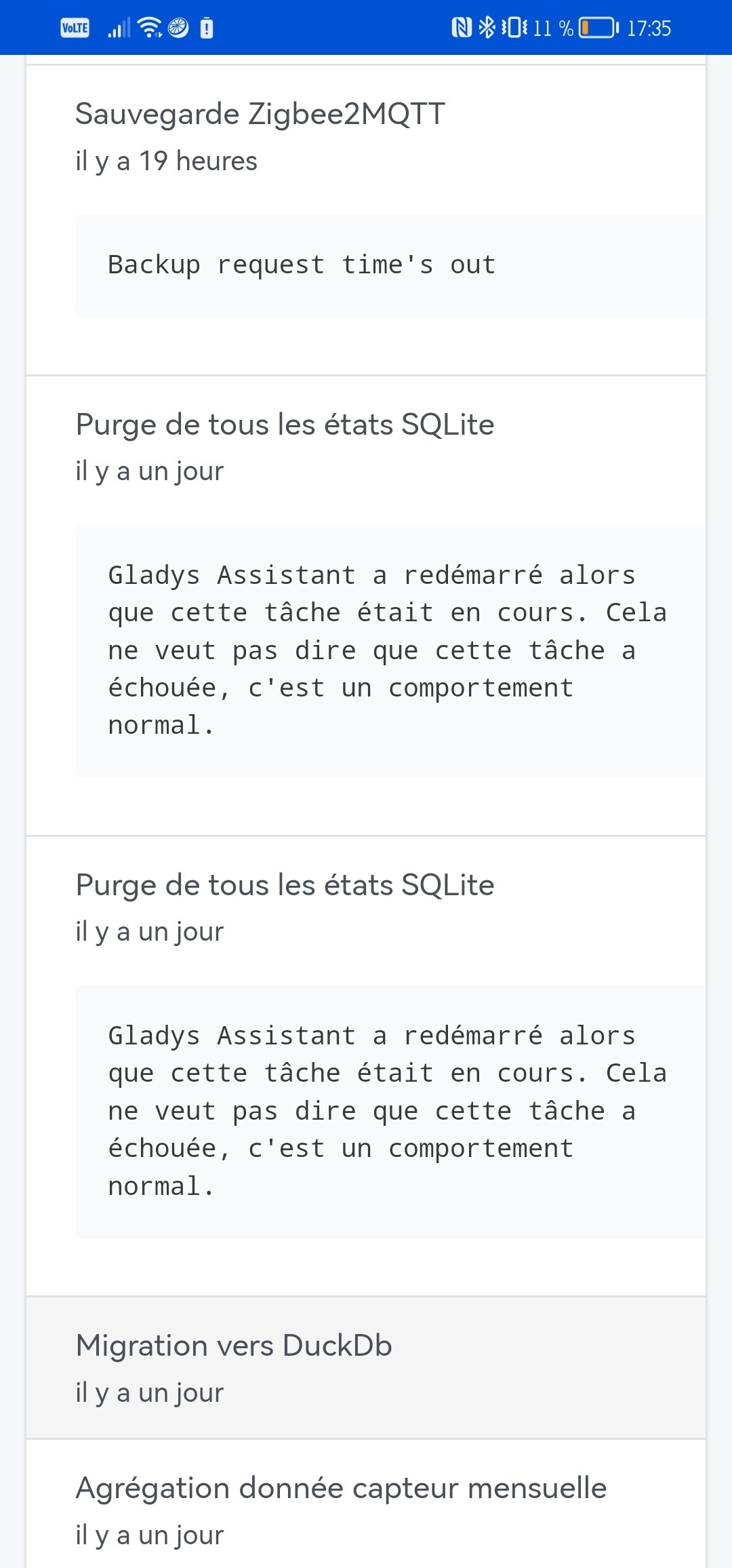
(There’s a typo: ‹ a échoué › would be more correct)
However:

So I start a database cleanup which, as expected, blocks Gladys for about an hour.
But after checking, I find that the old DB is not empty:

So I restarted the purge and DB cleanup steps and there you go (oh yes, and a manual container restart to clear the db-wal).

And since we were talking about backups, a screenshot of mine:

Obviously, it’s very small, if not uncompressed (is that still necessary?)
Total time… Nearly 30h…
We agree that the purge and cleanup steps are not essential but they allowed me to solve my storage problem