Hello everyone!
I’m creating this feature request even though it’s already quite advanced so that we can discuss it together on the forum and not just on GitHub.
For the timeline, @euguuu had started a first technical specification and had a first PR by the end of 2020. It was super complete and in terms of research, he went very far!! ![]()
However, the PR was not finished, and I did not agree with all the technical choices that had been made, so I started working on another PR from scratch based on the same research, but with a different implementation.
I started working on it this summer (mid-July), and it was not a simple development!
Concretely, my specification for this feature was:
- Display sensor values in less than 50ms regardless of the dataset (even 2 million sensor values)
- Ability to change the time frame in live by the dashboard user
- A super simple and clear UI.
- The background pre-calculation of aggregated sensor values should not slow down Gladys.
- The user should be able to know if these sensor data have been aggregated or if something went wrong.
For now, it looks like this:
The big challenge of this development is to calculate in the background the aggregated sensor values, and to do it without slowing down Gladys, and while communicating with the user.
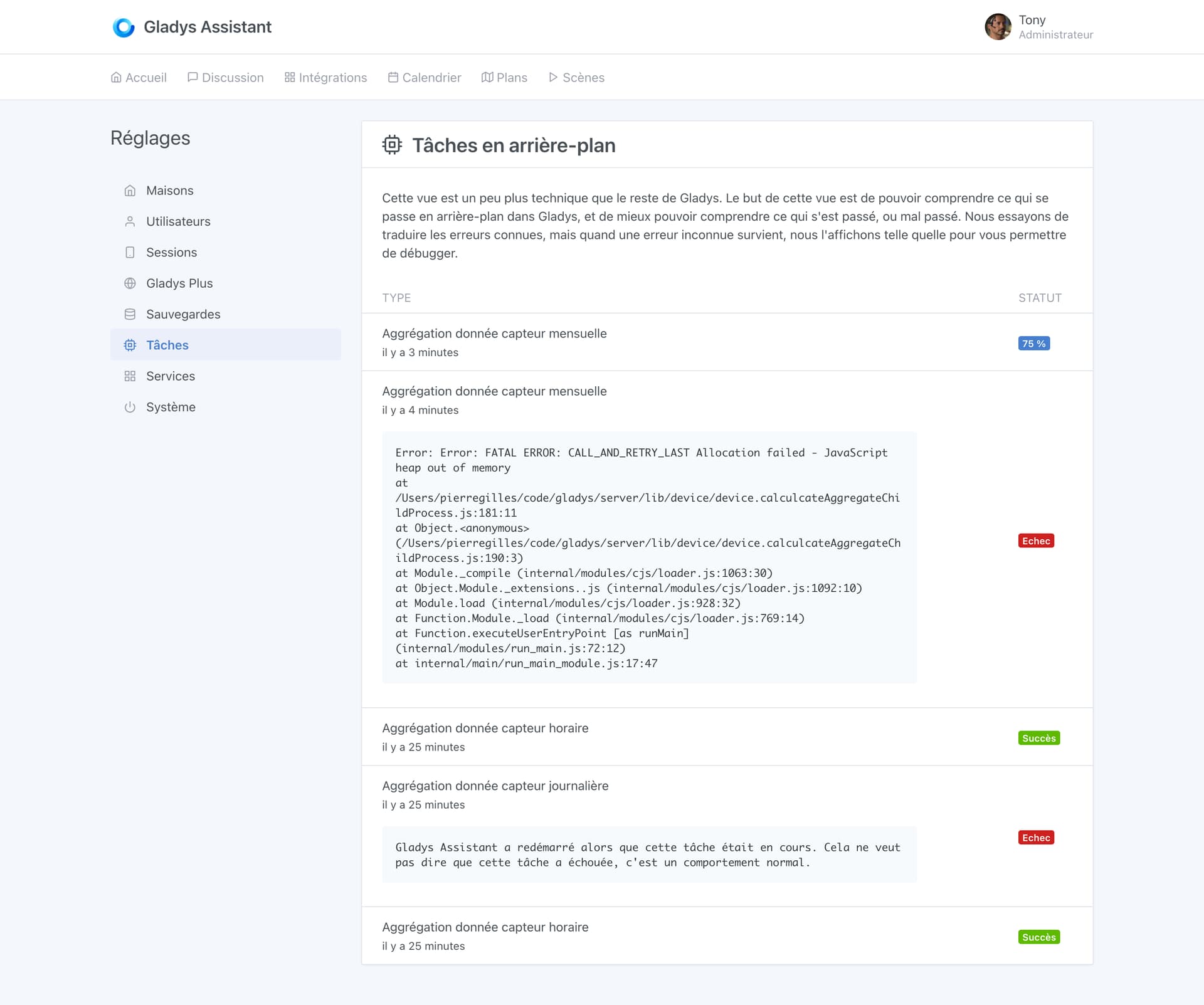
A new view therefore appears in Gladys, the « background tasks » view:

In the future, the goal is to integrate all background tasks (scenes, etc.) into this view to give the user more visibility into what is happening in the background in their Gladys.
My PR is available here:
I would appreciate any feedback @contributors ![]()