Improvement of device data history management: Integration of configurable granularity for state recording
Hello everyone,
I would like to propose an improvement aimed at optimizing how Gladys Assistant manages and stores the history of data received from connected devices. Currently, every state sent by a device for a given feature is recorded in the database, regardless of whether it has changed compared to the previous state. This method, while reliable for data retention, can lead to a rapid accumulation of redundant data, especially for devices that communicate at short intervals.
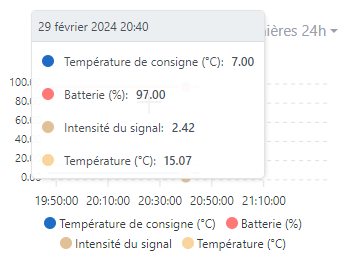
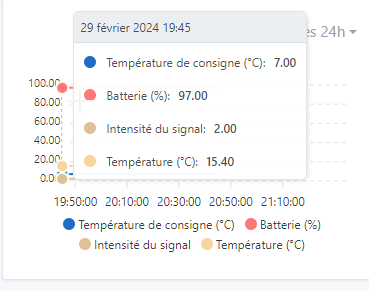
Current Issue: In the current context, a device sending its data every 30 seconds results in each received data point being recorded, even if it has not changed. This can quickly saturate the database with little-useful information, especially for data that require less fine granularity (for example, humidity or battery level that changes little).
Proposal: I propose allowing more flexible configuration of the recording granularity for each feature of a device. This could be done in two ways:
- Adding a global setting in the system settings allowing to define a period during which, if the data has not varied, it would not be recorded in the database. This period could be adjusted according to the user’s needs or left empty to maintain the current behavior (systematic recording). Quite simple to implement.
- Adding a specific column in the
t_device_featuretable to define the recording granularity per feature. This would offer maximum flexibility, allowing the recording frequency to be adjusted according to the nature and usefulness of each data point.
Advantages:
- Significant reduction in the volume of stored data, by keeping only essential information.
- Optimization of database performance, by limiting the number of writes.
- Greater customization for the user, who can adapt the recording behavior according to the specifics of their home automation setup.
Example:
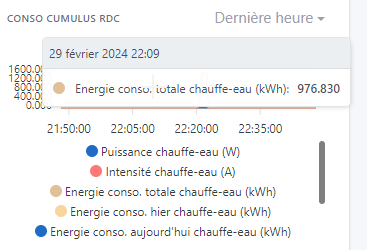
I installed a thermostat only 1 week ago. I want to remove it:

It already has 280,000 values even though it only polls every 2 minutes. And most values are identical. This would reduce the amount of data by at least 4 times (i.e., about 70,000).