Salut @spenceur
Est-ce que tu pourrais me donner le modèle de ta clé Zigbee ?
J’ai retourné mon problème dans tous les sens, réduit mon install au strict minimum et j’ai encore des erreurs d’agrégation. Beaucoup moins, mais j’en ai encore.
J’ai arrêté la VM qui faisait tourner Gladys et l’ait installée directement sur le NAS, branché la clé directement sur le NAS également, sans passer par un concentrateur, uniquement intégré une sirène et 7 capteurs d’ouverture, un compte Caldav, Enedis, et Gladys Plus.
@Philou changer le dongle ne va rien changer à mon avis
Une option que tu peux faire, serait d’aller récupérer le fichier SQLite, et de faire tourner une petite query SQL pour déterminer quel appareil envoie le plus de valeurs!
La DB est situé dans :
/var/lib/gladysassistant/gladys-production.db
Pense à stopper Gladys avant de récupérer le fichier pour éviter toute corruption.
Ensuite, tu récupère le fichier sur ton ordi en local (hors Gladys), et avec un outil genre TablePlus tu exécute la query suivante:
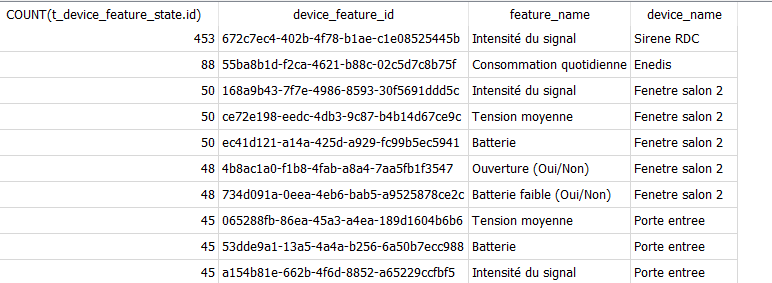
SELECT COUNT(t_device_feature_state.id), device_feature_id,
t_device_feature.name as feature_name, t_device.name as device_name
FROM t_device_feature_state
JOIN t_device_feature ON t_device_feature.id = device_feature_id
JOIN t_device ON t_device.id = t_device_feature.device_id
GROUP BY device_feature_id
ORDER BY COUNT(t_device_feature_state.id) DESC;
Ton instance date de quand ? 453 valeurs c’est rien
L’idée ici c’est de calculer combien de valeurs/seconde reçoit Gladys pour voir si un capteur est vraiment extrêmement agressif, mais là 453 valeurs si c’est sur quelques jours, c’est vraiment rien.
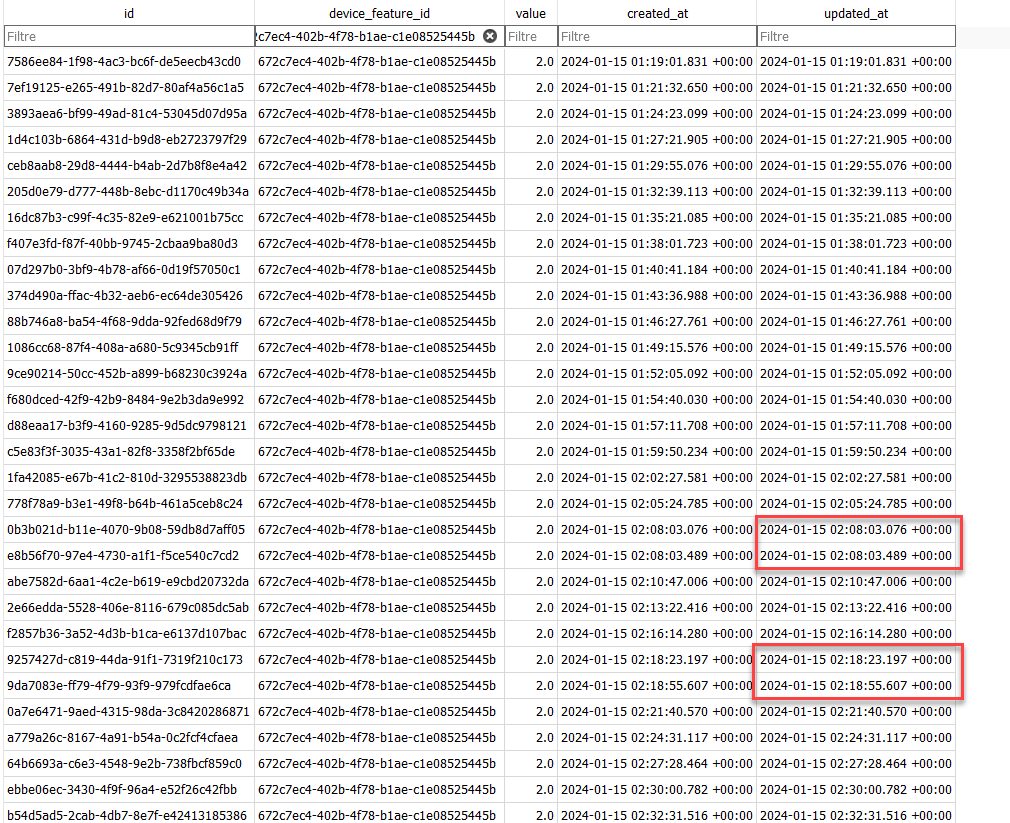
Tu peux aller voir la table t_device_feature_state et filtrer par ce capteur pour voir à quelle fréquence il envoie, mais ça me parait tout à fait correct là…
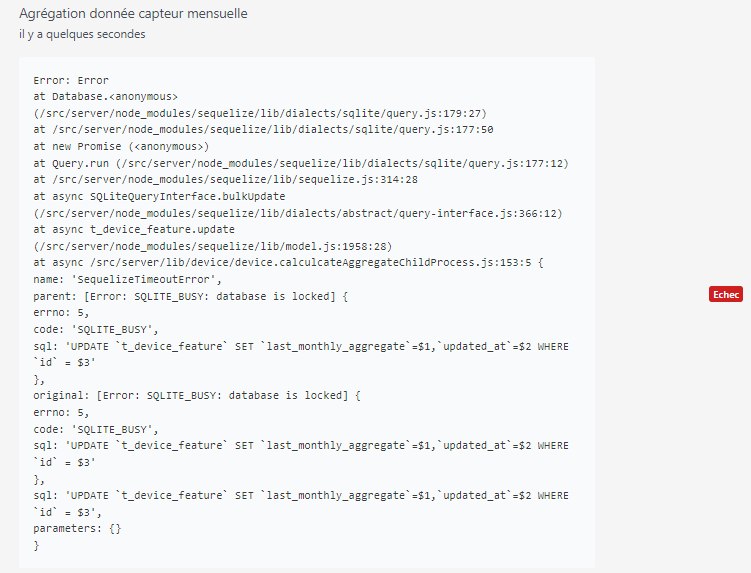
Hier matin et depuis plusieurs jours je n’avais que des échecs.
Fresh install en direct sur le NAS (sans VM), avec dongle en direct sur le NAS (sans concentrateur USB), j’ai ré-appairé tous mes devices et me suis retrouvé avec que des échecs à nouveau.
J’ai donc pris le parti d’une install minimum.
Depuis j’ai eu deux échecs, celui de cette nuit donc et un autre hier, 4h après l’install
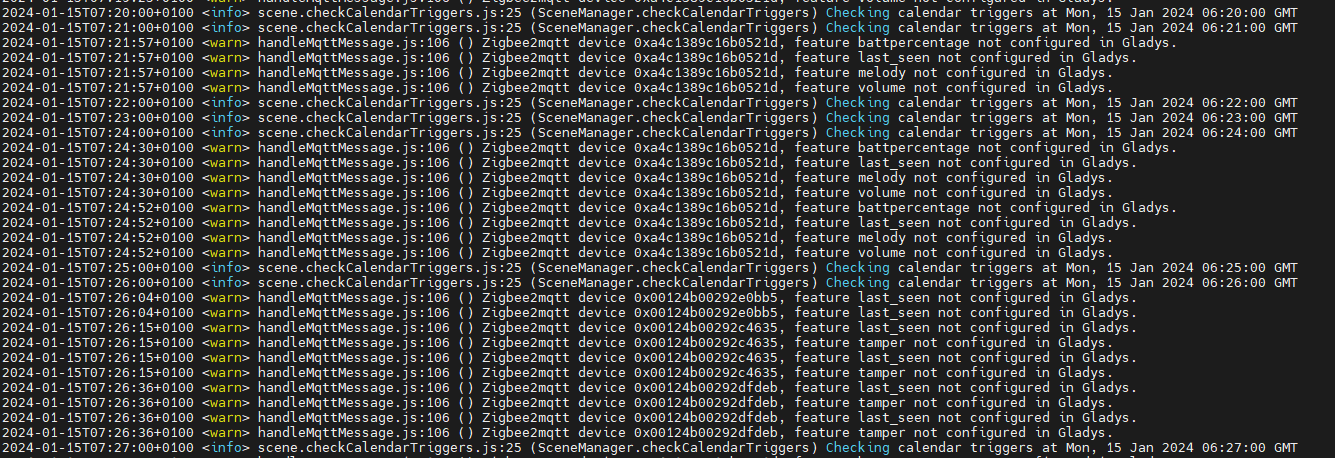
Je remarque également ces messages dans les logs qui indiquent que certaines features de la sirène ne sont pas prises en charge mais je doute que ce soit bloquant.
Ok, ça parait normal. Pas exceptionnel mais pas mauvais du tout
C’est un SSD? SSD NVMe? HDD?
Et sur ton NAS il y a des choses qui tournent en même temps j’imagine? Rien qui pourrait occuper le disque « à fond » et qui pourrait bloquer Gladys?
En fait il te faudrait un tool genre Netdata ( https://www.netdata.cloud/ / c’est gratuit et open-source), pour voir si il y a de l’activité sur ton NAS qui fait coincer tout
Je vais creuser, merci pour l’idée je n’y avais pas du tout pensé
J’avais un serveur Minecraft qui tournait j’ai commencé par le couper.
C’est RAID SHR (propriétaire Synology) sur 4 disques WD RED 5400 T/m de 2T, un disque de hot spare.
Oui j’ai un peu d’activité dessus, serveur mail, backups nocturnes, réplications croisées, serveur multimédia, un petit site web, bref de quoi faire bosser les disques mais rien de fou non plus.
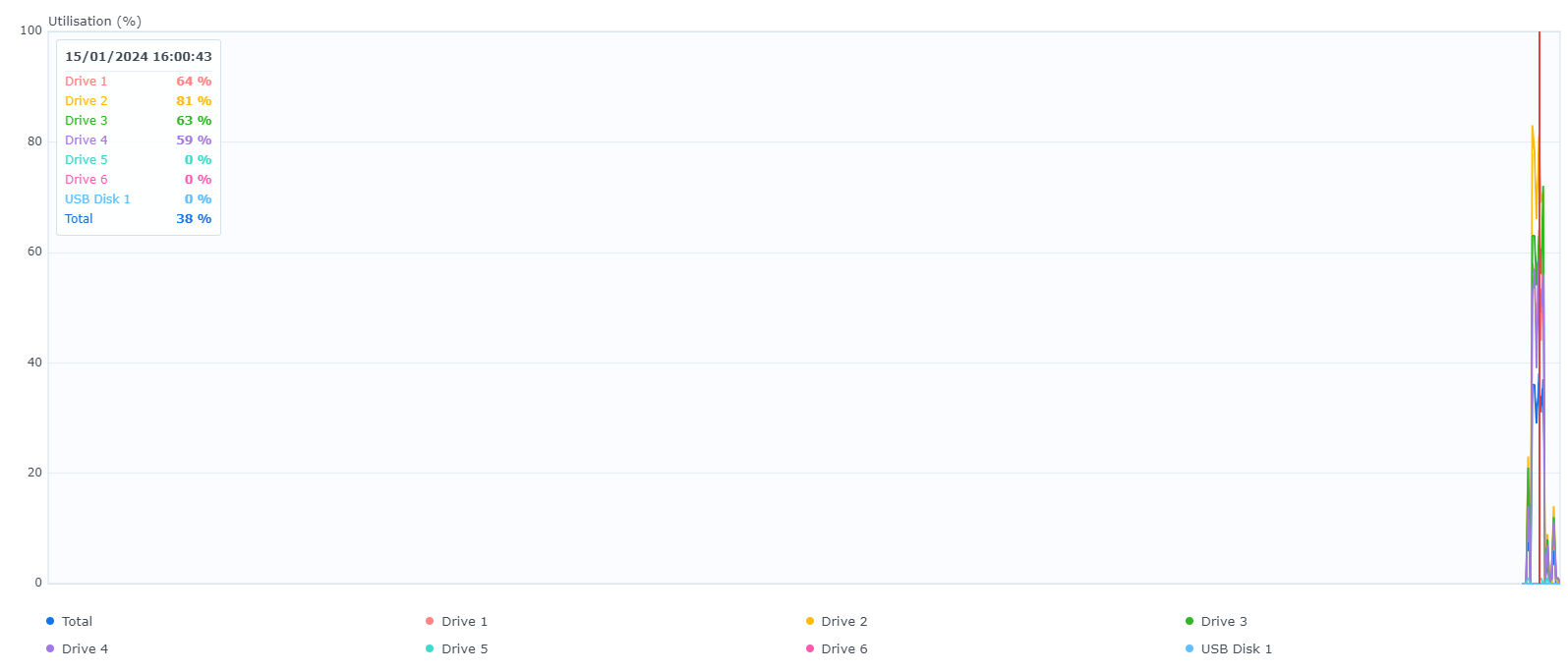
Par contre quand je regarde l’occupation des disques pendant les aggrégations… surprise !
Tu as moyen de brancher un disque supplémentaire ? Sinon met un SSD (pas en RAID) en plus et met le volume Docker Gladys dessus, au moins tu seras isolé + en SSD
Si il y a de l’activité disque au moment des agrégations c’est normal
Quitte à ajouter un SSD j’ai commandé un NVMe au format M2 dont je vais me servir comme cache pour l’ensemble de la grappe RAID, merci du conseil ! J’ai la chance d’voir un modèle qui le permet.
Pas encore, désormais quand je fais une modif aussi petite soit elle je laisse tourner quelques heures pour confirmer que c’est stable. Je viens d’en remettre un, je vais monitorer.
Petite update : tests toujours en cours.
J’ai pu ajouter 2 devices Xiaomi à mon rez de chaussée sans trop de problème, plutôt stable mais quand j’ajoute un périphérique de l’étage les aggregations commencent à planter.
Chez moi j’ai
dans mon garage (-1) NAS+Cle Zigbee, quelques capteurs de porte, capteur Xiaomi de Température
au RDC (0) plusieurs capteurs de portes, une prise sonof, une sirène Neo, un capteur Xiaomi, une bande LED Tuya.
au 1er, une prise Sonof, 4 capteurs Xiaomi déconnectés
au 2e, une seconde sirene Neo
En l’état ça fonctionne.
Je me suis aperçu que les associations Zigbee fonctionnent beaucoup mieux quand le « routeur » Zigbee (le clé USB) est proche. J’avais pas mal d’échec d’associations et les faire proche du routeur principal puis déplacer le device fonctionne mieux que de vouloir associer directement à l’emplacement final.
Et donc dès que j’ajoute un device de mon 1er étagé les aggregations commencent à planter.
Pas mal de tests en tête à faire pour trouver la root cause, la première étant l’ajout d’un cache NVMe sur mon NAS. J’ai bien commandé un premier NVMe au format M2 mais je viens d’apprendre qu’il en faut 2 pour que le cache soit en read/write et pas read only, Jen ai donc commandé un second.
Mainenant le Cache NVMe en place, les 3 aggrégations prennent 10 secondes là où elles prenaient 1 min 50,soit divisée par plus de 10. Jusque la j’avais le temps de voir les % augmenter, même reculer, pour augmenter à nouveau etc. Désormais c’est en ligne droite. La réactivité de l’interface est pour le moment juste excellente, au dessus de ce qu’elle était, et c’est tout mon NAS qui en profite. J’ai rajouté tous mes capteurs, la première aggrégation est passée crème, à suivre.
Que ça règle mon problème ou non, j’ai clairement sous estimé l’importance du stockage. Merci @pierre-gilles de m’avoir orienté dans cette direction