@cicoub13 I can reproduce your « Maximum Call Stack » by trying to chunk an array of 150k sensor values :o that means you have a sensor that sent more than 150k values aha, we haven’t had this case even at @Terdious, interesting
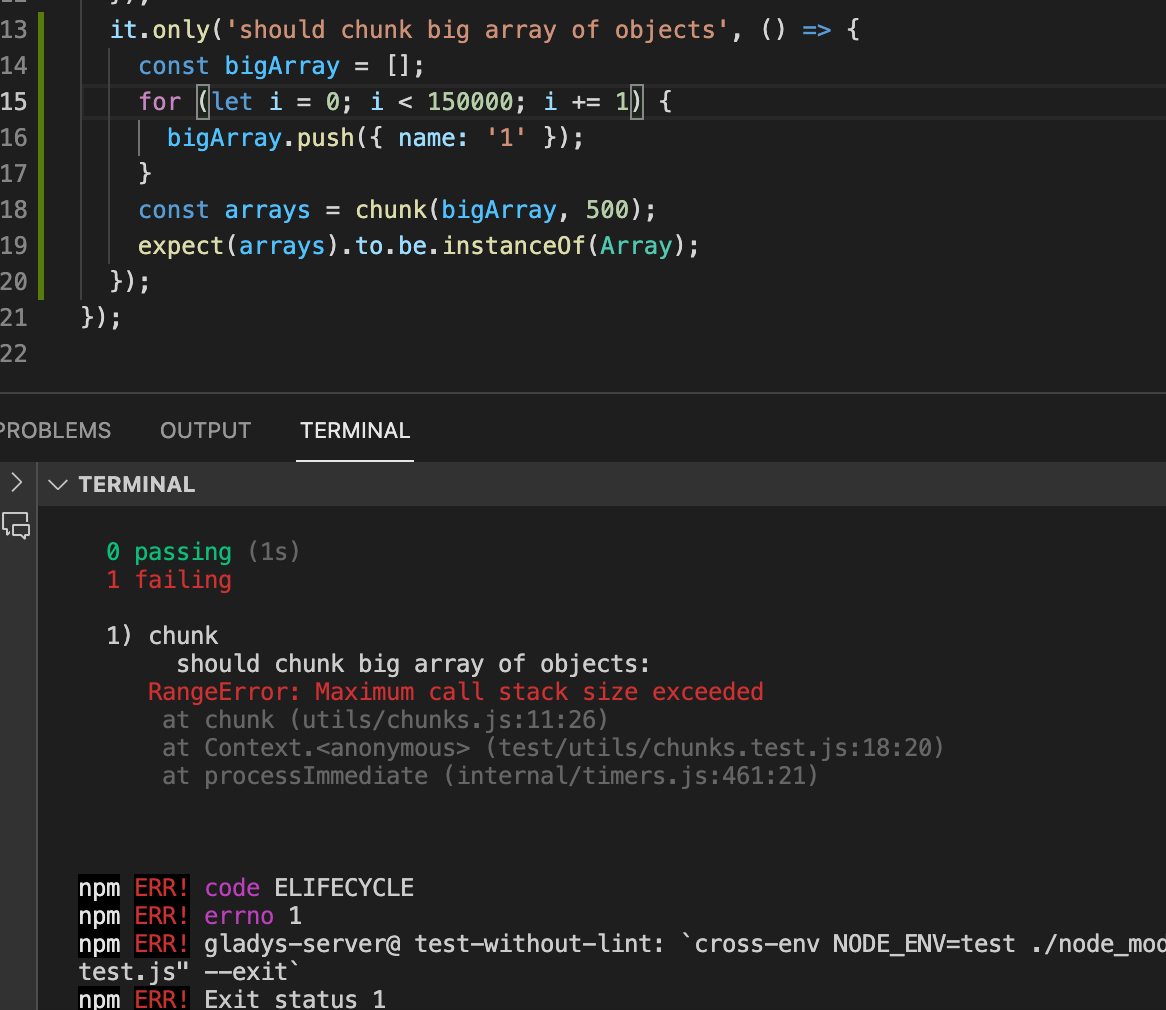
I found a more performant implementation than the one we currently have, and it uses « slice » instead of « splice », which means you don’t have to clone the array beforehand because the array is not mutated.
I based it on this:
A performance test confirms that the old implementation is 69.6% slower than the new one, and most importantly, the new one doesn’t have the Maximum Call stack issue since the array is not cloned.
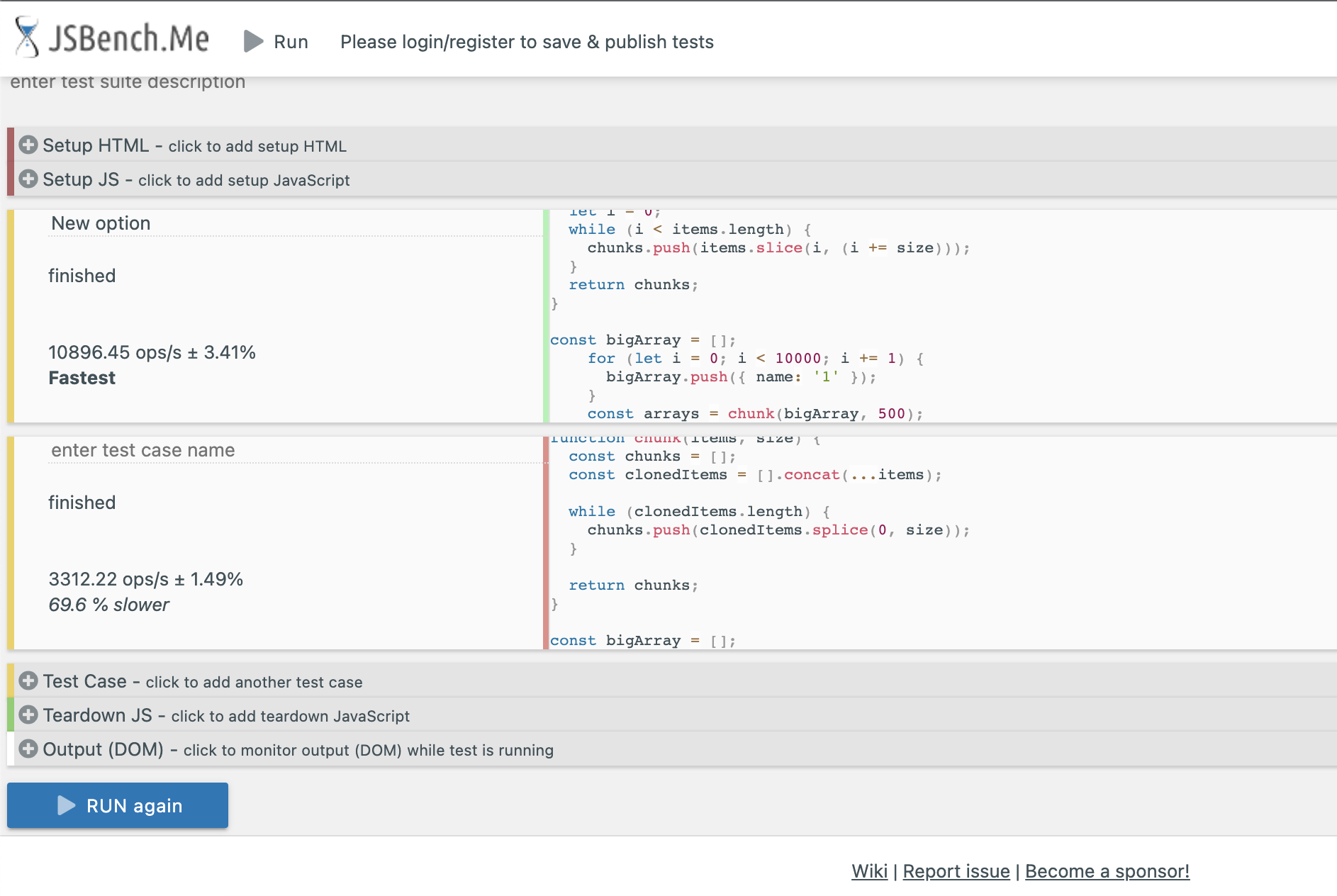
Here’s the PR for those interested:
I merged the PR and launched a build on the « dev » tag to see if that fixes the issue on your end @cicoub13 ![]() (on Docker it will be available on
(on Docker it will be available on gladysassistant/gladys:dev as usual)
The build is here:
https://github.com/GladysAssistant/Gladys/actions/runs/1397530669
It will take about an hour ![]()
792K deviceFeatureState
5 features with 124K records - They are all linked to a connected plug ![]() (it’s this model Tuya TS0121_plug control via MQTT | Zigbee2MQTT)
(it’s this model Tuya TS0121_plug control via MQTT | Zigbee2MQTT)
5 features with 15K records - Linked to a motion detector (which also measures light)
The number of records per day is quite regular and I only have 3 months of rolling data saved.
I’ll test this today
Here is what the API returns for this issue:
[{\"id\":\"c5bac8c2-5a49-4f7c-9ad8-0e367b427df8\",\"type\":\"hourly-device-state-aggregate\",\"status\":\"failed\",\"progress\":52,\"data\":{\"error_type\":\"purged-when-restarted\"},\"created_at\":\"2021-10-28 09:14:48.379 +00:00\",\"updated_at\":\"2021-10-29 06:03:07.825 +00:00\"},{\"id\":\"83bca935-43d3-4177-ba38-e51a16c36ff6\",\"type\":\"monthly-device-state-aggregate\",\"status\":\"success\",\"progress\":97,\"data\":{},\"created_at\":\"2021-10-28 09:04:14.845 +00:00\",\"updated_at\":\"2021-10-28 09:04:16.830 +00:00\"},{\"id\":\"6f15c4b3-5acb-4747-88b3-730af6fdecc4\",\"type\":\"daily-device-state-aggregate\",\"status\":\"success\",\"progress\":97,\"data\":{},\"created_at\":\"2021-10-28 09:04:12.809 +00:00\",\"updated_at\":\"2021-10-28 09:04:14.837 +00:00\"},{\"id\":\"2e0b5f3e-bf82-4a8c-a4c5-d601a209a10b\",\"type\":\"hourly-device-state-aggregate\",\"status\":\"failed\",\"progress\":52,\"data\":{\"error_type\":\"unknown-error\",\"error\":\"Error: RangeError: Maximum call stack size exceeded\\n at chunk (/src/server/utils/chunks.js:11:26)\\n at /src/server/lib/device/device.calculcateAggregateChildProcess.js:147:22\\n\"},\"created_at\":\"2021-10-28 09:03:22.151 +00:00\",\"updated_at\":\"2021-10-28 09:04:12.802 +00:00\"}]
Should we modify the Zigbee2Mqtt integration to not record the value if it hasn’t changed? It would be a shame, as we could lose information (the lack of variation is information).
Were you able to test it in the end? ![]()
Very strange, it seems fine!
I don’t think so, it’s indeed important to keep the values even if they haven’t changed.
However, what we could do is display the « keep_history » attribute of each feature in the UI (as a toggle), to eventually allow the user to not record the history of some too verbose devices/and where the history doesn’t interest them:
Yes, but the aggregation remains stuck at 52% (after that, I lose control of my RPI 3B+).
The CPU is at 100% and the RAM is full. And it never ends.
I tried by removing the states of the 2 verbose devices (which I don’t use for the graphs) and it works. I think you can leave your optimization in master.
I really need to invest in an RPI4 and an SSD ![]()
Thanks anyway for the investigation and the correction ![]()
I created an issue to keep the keep_history option
https://github.com/GladysAssistant/Gladys/issues/1344
Oh crap, indeed if you have 1GB of RAM and part of it is already taken by other things, if Gladys tries to load 130k sensor values into RAM + try to aggregate this data hour by hour, it can overload the RAM and thus it never completes…
In the UI, do you have a clear error when it’s a RAM issue?
Ok great! Otherwise, you can also tell Gladys to keep only the last 3 months of sensor values in the settings ![]()
No, it never completes and there’s no error.
I’ll do that while waiting for the development that will prevent recording values for these two devices.
If it’s too blocking, change the keep history in db
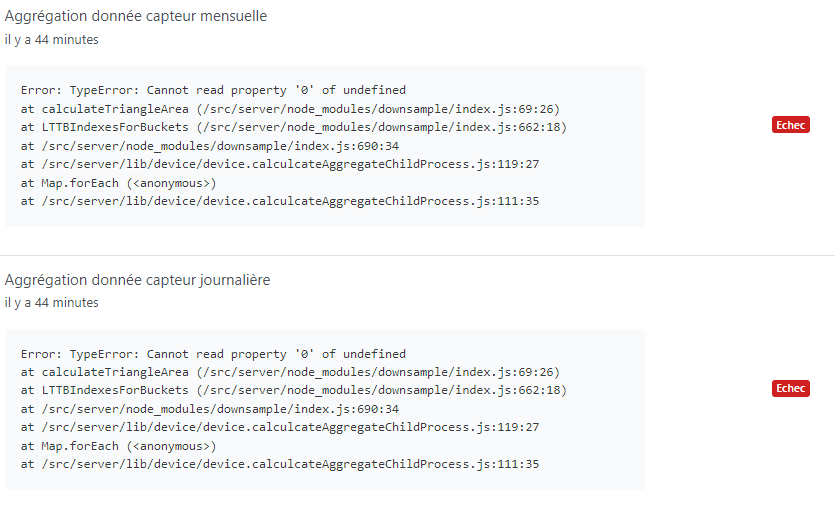
I restarted Gladys to check, and I still have the same errors:
2021-11-25T12:46:18+0100 <warn> device.calculateAggregate.js:95 (Socket.<anonymous>) device.calculateAggregate stderr: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
2021-11-25T12:46:18+0100 <warn> device.calculateAggregate.js:101 (ChildProcess.<anonymous>) device.calculateAggregate: Exiting child process with code 1
2021-11-25T12:46:18+0100 <error> device.onHourlyDeviceAggregateEvent.js:22 (DeviceManager.onHourlyDeviceAggregateEvent) Error: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
at ChildProcess.<anonymous> (/src/server/lib/device/device.calculateAggregate.js:102:23)
at ChildProcess.emit (events.js:400:28)
at maybeClose (internal/child_process.js:1058:16)
at Process.ChildProcess._handle.onexit (internal/child_process.js:293:5)
2021-11-25T12:46:18+0100 <info> device.calculateAggregate.js:38 (DeviceManager.calculateAggregate) Calculating aggregates device feature state for interval daily
2021-11-25T12:46:58+0100 <warn> device.calculateAggregate.js:95 (Socket.<anonymous>) device.calculateAggregate stderr: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
2021-11-25T12:46:58+0100 <warn> device.calculateAggregate.js:101 (ChildProcess.<anonymous>) device.calculateAggregate: Exiting child process with code 1
2021-11-25T12:46:58+0100 <error> device.onHourlyDeviceAggregateEvent.js:27 (DeviceManager.onHourlyDeviceAggregateEvent) Error: TypeError: Cannot read property '0' of undefined
at calculateTriangleArea (/src/server/node_modules/downsample/index.js:69:26)
at LTTBIndexesForBuckets (/src/server/node_modules/downsample/index.js:662:18)
at /src/server/node_modules/downsample/index.js:690:34
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:119:27
at Map.forEach (<anonymous>)
at /src/server/lib/device/device.calculcateAggregateChildProcess.js:111:35
at ChildProcess.<anonymous> (/src/server/lib/device/device.calculateAggregate.js:102:23)
at ChildProcess.emit (events.js:400:28)
at maybeClose (internal/child_process.js:1058:16)
at Process.ChildProcess._handle.onexit (internal/child_process.js:293:5)
2021-11-25T12:46:58+0100 <info> device.calculateAggregate.js:38 (DeviceManager.calculateAggregate) Calculating aggregates device feature state for interval monthly
If it can help with the investigation, I can send you my DB or perform specific analyses.
@lmilcent I admit I completely forgot about this bug! I can’t reproduce it on my end, but based on your logs, it looks like a specific dataset that’s crashing the downsampling library we’re using (downsample on npm).
Could you create a GitHub issue on the Gladys repo (otherwise, in 10 minutes I’ll forget :p), and send me a DB where the issue actually occurs (that would be great for debugging ![]() )?
)?
Thanks!
@lmilcent Thanks! I’ve edited the issue title. (the NaN bug is a different bug, nothing to do with it ![]() )
)
Same error on my end regarding aggregation. In my case, it seems to come from the data from cryptocurrencies (Shiba) which is always below 0. I wonder if it’s not due to the number of decimals taken into account in the calculation used by the library for its aggregation:
It works for the last hour as I retrieve the info every 5 minutes (so probably no aggregation) but not for the day or the month.
Thank you for your message @Albenss, I think some aggregations may have failed due to a similar case.
For example, my MQTT device for managing presence was receiving « present » before receiving « 1 » now.
But I made the change several months ago, and there are still failures.
In general, the error should be more precise ![]()
@lmilcent I just looked at the database you sent me, and I’m very surprised by its content ![]()
You have device_feature_state values that are « NaN » (Not a Number). It’s very strange that this was inserted, given that the field is a « double precision », and « NaN » is not a double precision…
Of course, this crashes the aggregation that expects numerical values, not a string.

After investigation, these values come from the Zigbee2mqtt integration.
I created a GitHub issue to fix the problem:
- Add a DB migration to clean up these lines that shouldn’t be there
- See why the validation and the DB accepted these values that are not Numbers.
In the meantime, @lmilcent and @Albenss, the SQL query to fix your DBs is:
DELETE FROM t_device_feature_state WHERE value = 'NaN';
@lmilcent More generally, I don’t know if you keep all your historical sensor data (you keep them all), but I would advise you to clean up some very verbose deviceFeatures, because currently to perform the aggregation on my Mac, some sensors contained so many values that it took more than 1.5 Gb of RAM to perform the total aggregation (since it’s a first aggregation, it starts from the beginning. This will not be the case later)
Otherwise, by removing the NaN, it works very well for me on your DB:
I have started the removal of incorrect values. I will check the other equipment that is verbose… Function to be planned? ![]()