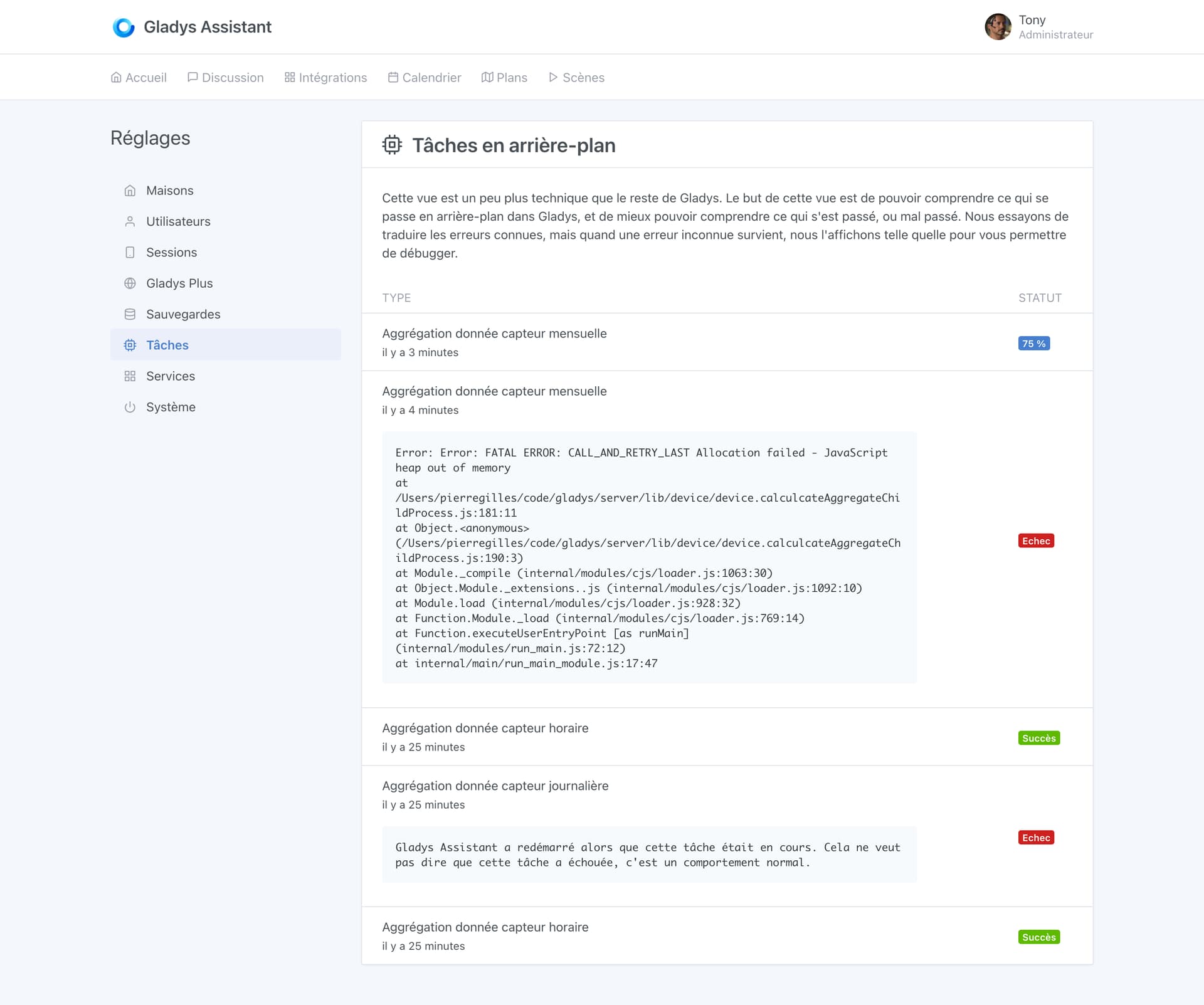
Petite preview de sur quoi je bosse depuis ce matin, un affichage clean des erreurs dans la vue “tâches en arrière-plan” ! 
J’ai toujours été contre l’affichage des logs pures dans l’UI (car on sait ce que ça donne, ensuite on est flemmard et on fait des intégrations où on demande aux gens d’aller chercher des IDs dans les logs  ), en revanche je suis pour une vue de ce style, où:
), en revanche je suis pour une vue de ce style, où:
- Toutes les erreurs connues sont traduites, et la marche à suivre est clairement expliquée pour l’utilisateur. Exemple ici avec une erreur simple: Gladys a redémarré alors qu’une tâche tournait: c’est un comportement normal, et il faut le préciser.
- Pour les erreurs inconnues, on l’affiche telle quelle pour que l’utilisateur puisse nous faire un retour, ensuite deux solutions:
- C’est un bug, on corrige le bug
- C’est une erreur qui peut arriver dans certains conditions (pas un bug): Exemple “OUT_OF_MEMORY”/“DISK FULL”, etc… Dans ce cas, on ajoute cette erreur à la liste d’erreur traduite, avec un message clair, et avec une marche à suivre pour résoudre l’erreur.
Voilà à quoi ressemble la vue pour l’instant:
Vous en pensez quoi ?