Salut à tous!
Je créé cette demande de fonctionnalité malgré le fait qu’elle soit déjà bien avancée pour qu’on puisse en parler ensemble sur le forum et pas juste sur GitHub.
Pour la timeline, @euguuu avait commencé à faire une première spécification technique et avait une première PR dès fin 2020. C’était super complet et niveau recherche il était allé très loin !! 
Néanmoins la PR n’était pas terminée, et je n’étais pas d’accord avec tous les choix techniques qui avaient été fait, j’ai donc commencé à travailler sur une autre PR from scratch basé sur les même recherches, mais avec une implémentation différente.
j’ai commencé à travailler dessus cet été (mi-juillet), et c’était pas un développement simple !
Concrètement, ma spécification pour cette fonctionnalité c’était:
- Affichage de valeurs de capteurs en moins de 50ms quel que soit le dataset (même 2 millions de valeurs de capteurs)
- Possibilité de changer la temporalité en live par l’utilisateur du dashboard
- Une UI super simple et claire.
- Le pré-calcul en arrière-plan des valeurs de capteurs agrégées ne doit pas ralentir Gladys.
- L’utilisateur doit pouvoir savoir si ces données de capteurs ont été agrégée ou si quelque chose s’est mal déroulée.
Pour l’instant, ça ressemble à ça:
Le grand défi de ce développement, c’est de calculer en arrière-plan les valeurs de capteurs agrégées, et le faire sans ralentir Gladys, et en communiquant avec l’utilisateur.
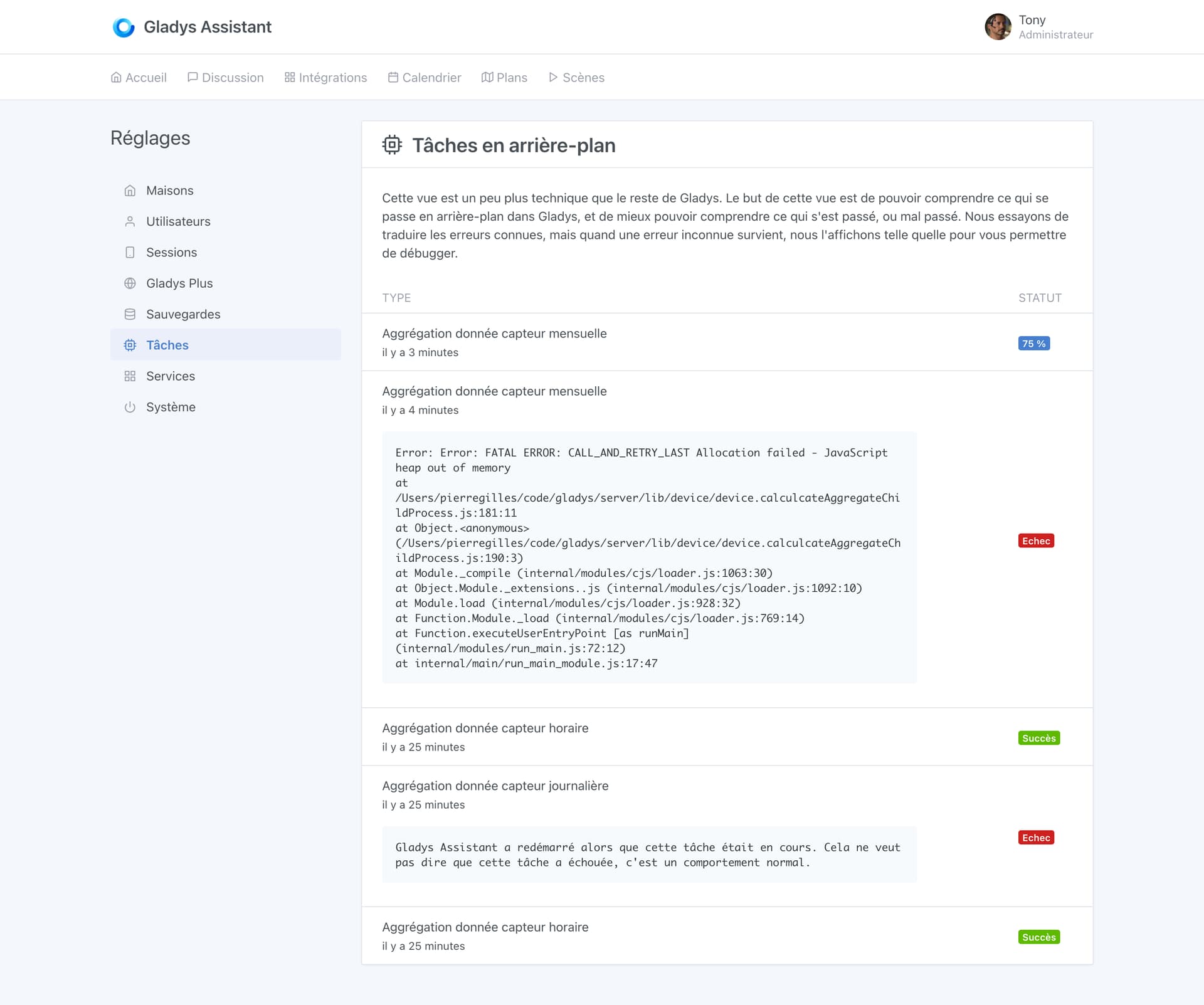
Une nouvelle vue apparait donc dans Gladys, la vue “tâches en arrière plan”:

A l’avenir, le but est d’intégrer toutes les tâches en arrière plan (scènes, etc…) à cette vue pour donner plus de visibilité à l’utilisateur sur ce qu’il se passe en arrière plan dans son Gladys.
Ma PR est disponible ici:
Je serais preneur de tout retour @contributors


 ), en revanche je suis pour une vue de ce style, où:
), en revanche je suis pour une vue de ce style, où: