C’est une image pour quelle plateforme ?
Forcément ça tourne pas :
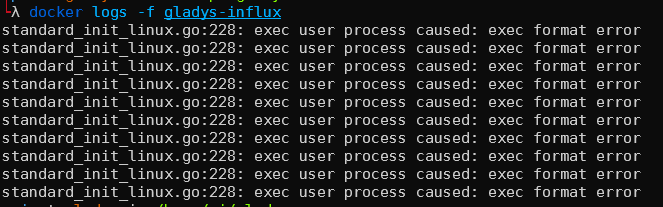
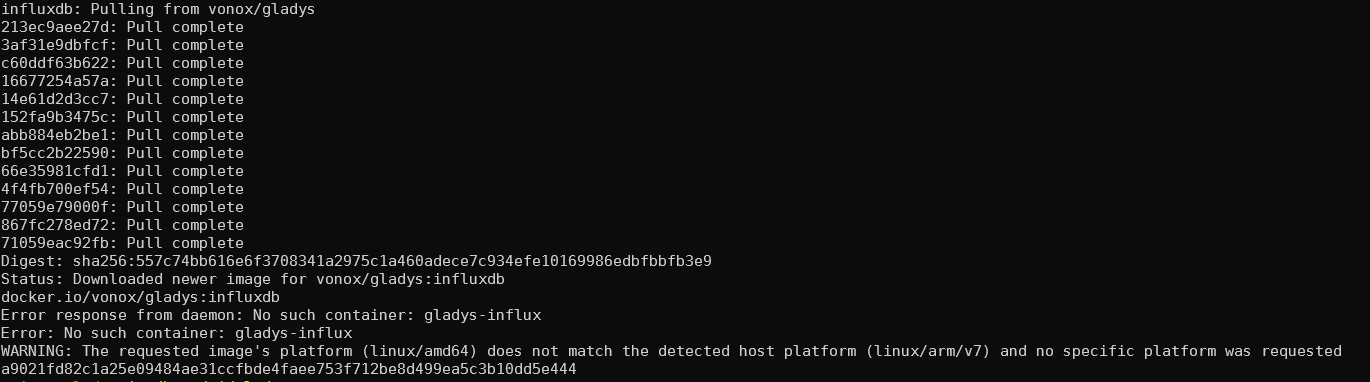
Bien vu amd64, je vais build les autres platform ( c’était que pour moi à la base ![]() )
)
@lmilcent C’est build pour toutes les platforms hésite pas à faire des feedbacks
Cool merci je vais tester aussi👍
Merci encore d’avoir pris le temps de le faire !
Pour le moment j’ai deux remarques :
Pour le moment j’ai testé deux images docker, qui ne tournent pas sur mon Raspberry Pi (pas la bonne architecture). L’image officielle ne propose que du amd64.
C’est le principe des bases de données “time-series”, c’est fait pour ingérer de la donnée temporelle comme ici, en utilisant peu de stockage et requêtable rapidement !
Déjà dans InfluxDB, il y a moins de donnée stockée pour chaque état: seulement 1 valeur + son timestamp associé.
Ensuite, sur disque ce genre de base de donnée font de la compression/décompression à la volée. Je suis pas expert InfluxDB, mais son concurrent TimescaleDB (basé lui sur PostgreSQL) parle de 90% de réduction de taille sur disque avec peu de perte de performance en lecture
Ce genre de mécanisme est possible car ces DB s’attaque à un seul problème (les données time séries), et peuvent donc prendre des raccourcis que les base de données relationnelle générique ne peuvent pas prendre !
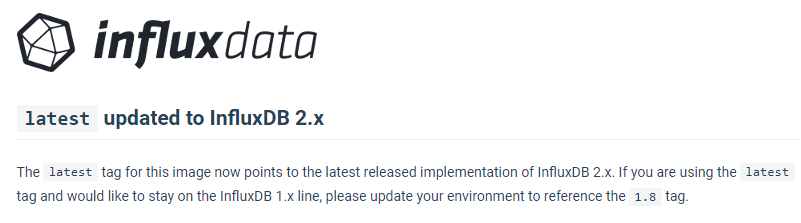
Je viens de déployer la version 1.8 de InfluxDB.
A priori la version 2.0 n’est pas compatible 32bits, il faudra donc une version du RasperryPI en 64bits pour en profiter.
echo "starting influxdb container"
docker run -d \
--name gladys-influxdb \
-p 8086:8086 \
-v /var/lib/gladysassistant/influxdb/data:/var/lib/influxdb \
-v /var/lib/gladysassistant/influxdb/config:/etc/influxdb \
-e DOCKER_INFLUXDB_INIT_MODE=setup \
-e DOCKER_INFLUXDB_INIT_USERNAME=gladys \
-e DOCKER_INFLUXDB_INIT_PASSWORD=gladysassistantinfluxdbtest \
-e DOCKER_INFLUXDB_INIT_ORG=gladys \
-e DOCKER_INFLUXDB_INIT_BUCKET=gladys \
-e DOCKER_INFLUXDB_INIT_RETENTION=10y \
-e DOCKER_INFLUXDB_INIT_ADMIN_TOKEN=my-super-secret-auth-token \
influxdb:1.8
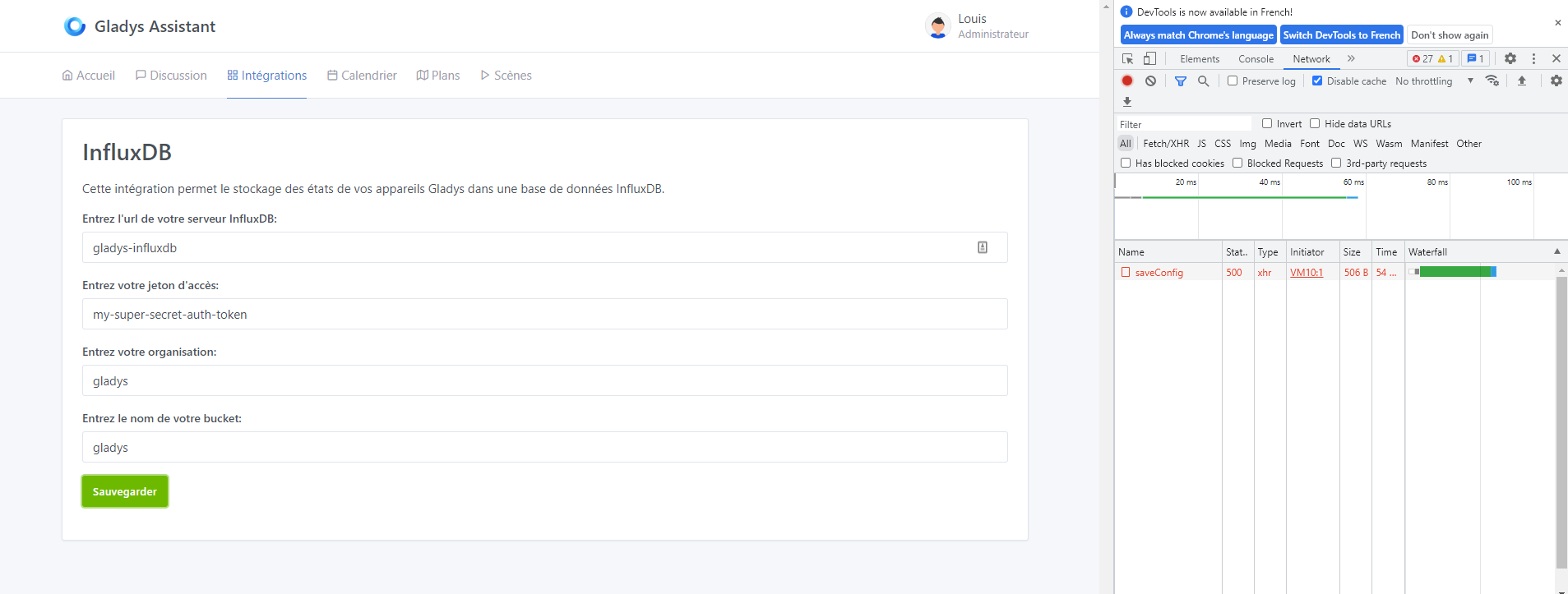
![]() Premier bug : pas de gestion des erreurs (code 500). L’interface n’affiche rien, pourtant la requête renvoie une erreur.
Premier bug : pas de gestion des erreurs (code 500). L’interface n’affiche rien, pourtant la requête renvoie une erreur.
![]() Deuxième retour : je ne comprenais pas comment former l’URL. Finalement j’ai compris, il faut mettre
Deuxième retour : je ne comprenais pas comment former l’URL. Finalement j’ai compris, il faut mettre http au début (voir l’image en dessous).
![]() Bug 2 : pas de retour sur la validation de la configuration. Code 200 avec
Bug 2 : pas de retour sur la validation de la configuration. Code 200 avec success, mais rien dans l’interface Gladys qui le confirme.
Pour le moment je n’ai pas encore lancé un Graphana pour consommer les données d’InfluxDB, par manque de temps, mais ça va venir !
Je questionne cette proposition, quel serait l’intérêt de proposer un lancement automatique ?
Dans le cas du Zigbee2mqtt, le but est d’avoir un service Zigbee en self-service utilisable sans jamais sortir de Gladys. On utilise Zigbee2mqtt sous le capot mais l’utilisateur n’a pas forcément à intéragir avec ce logiciel.
Dans le cas d’InfluxDB, l’idée ici est de permettre à un utilisateur avancé qui sait ce qu’il fait d’exporter sa data
Si on met l’intégration InfluxDB en self-service, on sous entend que c’est utilisable « tel quel » par le grand public, ce qui n’est pas le cas !
Je suis d’accord, surtout que là tu n’as pas de documentation.
Aussi, ça n’est généralement pas le même serveur ( on évite de mettre tous ses œufs dans le même panier )
Je te rejoins sur les autres points, comme je l’ai dit c’est de l’alpha ![]()
Je comprends tout à fait vos points de vue et ça se défend.
J’aime bien de mon côté, quand la solution propose une possibilité « clé en main » et une autre plus manuelle.
Par exemple :
Sachant que pour le service Zigbee il existe déjà des scripts de déploiement docker tout fait, ça serait pas un trop gros boulot à faire (je pense).
Mais c’est aussi vrai pour tout ce que vous avez évoqué, c’est plus un choix stratégique sur la vision de Gladys ![]()
C’est pas une question de boulot ici, c’est vraiment une question de public et de perception.
Ma vision: je pense qu’un utilisateur lambda ne doit pas utiliser ce service, et a tout en interne dans Gladys pour faire son tableau de bord domotique avec ces belles courbes ![]()
Le service InfluxDB est un service avancé, destiné à un utilisateur qui a de l’expérience avec InfluxDB et qui sait quoi faire de la data ensuite. Parce que bon InfluxDB c’est sympa, mais comme lancer un PostgreSQL, derrière il faut un consommateur de la DB: un Grafana par exemple. Une fois que t’as la tête dans InfluxDB + Grafana, tu te dis « ah ouai c’est quand même pas pour tout le monde ».
J’ajoute un deuxième point qui me parait important: pour l’utilisateur lambda, Gladys = OS.
A partir du moment où c’est Gladys qui lance le container, l’utilisateur s’attend à ce que lorsqu’il restaure son instance (via Gladys Plus par exemple, ou une sauvegarde manuelle), tout revienne en place, car il pense que Gladys c’est l’OS complet de son système et qu’une sauvegarde est une sauvegarde complète. Si InfluxDB est accessible en un clic, alors il s’attend que tout le cycle de vie soit accessible en un clic. D’un coup ça devient complexe !
C’est une des raison pour laquelle je ne pense pas qu’un bouton Node-RED en un clic soit une bonne idée, ça créé la perception que Gladys devienne « responsable » de ces services qu’on ne maitrise pas du tout.
Pas de tag 2.0 => mais latest ( regarde mon screen plus haut )
Donc docker pull arm32v7/influxdb:latest
Hello, je me permet de rebondir dessus !
Je suis partiellement d’accord avec ce point de vu, en effet, de ton point de vu, il ne faut pas que Gladys ne devienne une usine a GAZ mais, j’ai lu beaucoup de message allant dans l’autre sens aussi de ta part.
En effet a chaque discours quand gladys n’est pas ou plus compatible avec une techno tu pronnes l’utilisation de nodered en //.
Or, pour un utilisateur qui souhaite juste tout mappé dans un logiciel domotique, tu leurs fait peur en leur demandant d’executer des lignes pour lancer nodered ou bien en leurs disant d’attendre un dev.
Je sais que tout ça c’est du temps, mais un deploy d’une image docker, je suis pas sur que ce soit compliqué et long surtout pour ces users ![]()
Je reviens sur le ZWave un peu et je pense qu’il faudrait priorisé ses technos quand même bien répendu (avant le zigbee du moins) pour attiré du monde et des dev. Après c’est mon point de vu perso ![]()
(en me relisant, j’ai l’impression que mon message est peut être trop agréssif, mais ce n’est pas le but srry ^^')
Tu confond plusieurs sujets assez différent et je pense que tu prend à l’envers ce que je dis.
Justement, si un utilisateur ne sait pas lancer un container Docker, alors il n’a pas à utiliser le service InfluxDB, c’est un service pour utilisateur avancé. On ne veut pas que ce se service soit utilisé par des débutants. Gladys reste un programme accessible à tous, et contrairement à d’autres solutions on ne veut pas pousser des programmes complexe comme InfluxDB.
Néanmoins, certains utilisateurs avancés peuvent avoir envie d’utiliser ces programmes, d’où cette intégration qui n’est pas pour tout le monde. On peut éventuellement rajouter un gros warning pour mettre ce point au clair dans l’intégration.
Node-RED est un programme complémentaire pour ceux qui veulent utiliser Gladys mais ne trouve pas les bonnes compatibilités dans Gladys. C’est un programme avancés, pas accessible à tous, et ce n’est pas une fin en soit. Je pense que montrer que cette solution existe est une bonne chose, mais je n’ai jamais dis que c’était l’avenir du projet.
Oui j’aimerais comme toi qu’on ait toutes les intégrations du monde dans Gladys, mais les intégrations ne tombent pas du ciel comme tu as pu le constater.
Ce n’est pas le sujet ici, ça fait un an et demi que l’intégration ZwaveJS2mqtt est en cours de développement par différents développeurs. Si tu veux que le sujet avance, je t’invite à aller sur ledit sujet et à proposer ton aide. Gladys est un projet collaboratif et open-source, et la productivité du projet ne dépend que de la productivité de ses membres.
Salut @VonOx,
Je viens de mettre en place mon serveur InfluxDB sur un serveur dédié, différent de GladysAssistant.
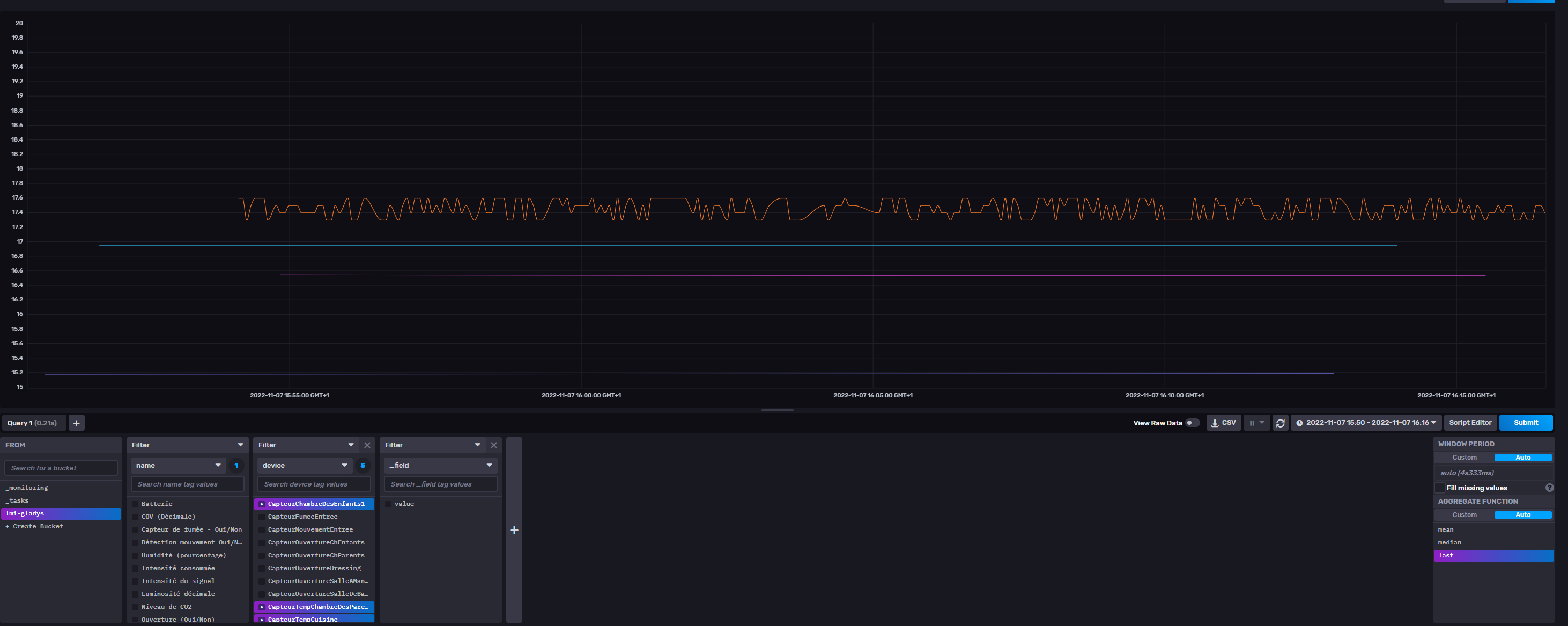
![]() Connexion fonctionnelle entre Gladys et Influx
Connexion fonctionnelle entre Gladys et Influx
![]() Comme je l’ai déjà dis, pas de message dans l’UI pour le confirmer
Comme je l’ai déjà dis, pas de message dans l’UI pour le confirmer
![]() Influx reçoit et détecte très rapidement les messages reçus
Influx reçoit et détecte très rapidement les messages reçus
![]() Grosse utilisation du CPU détectée !
Grosse utilisation du CPU détectée !
J’ai déployé une nouvelle instance de Gladys sur mon raspberry pi (juste un autre port) sur un clone de ma base de données. Elle reçoit donc les mêmes messages de Z2M, mais j’ai désactivé toutes les scènes, supprimé la plupart des dashboards et enfin déconnecté Gladys Plus.
Malgré tout ça, le conteneur utilise minimum 60% du CPU en moyenne, quand celui de Gladys tourne autour de 10%.
@VonOx ou @pierre-gilles avez-vous une idée de comment confirmer mon hypothèse : le service InfluxDB consomme beaucoup de CPU ?
A chaque nouvel état il y’a une requête http vers influx, a part voir avec la commu influxdb je sais pas trop quoi te dire ( rpi trop juste pour ça ?)