En réalité je m’étonnais plutôt de la quantité de CPU utilisé en plus par rapport à Gladys sans le service. Une requête HTTP sortante serait si consommatrice de CPU ?
Ne faudrait-il pas alors faire une sorte de « batch », basé sur une quantité d’événements ou un délai ? Par exemple : toutes les 10 « values » ou 5 secondes.
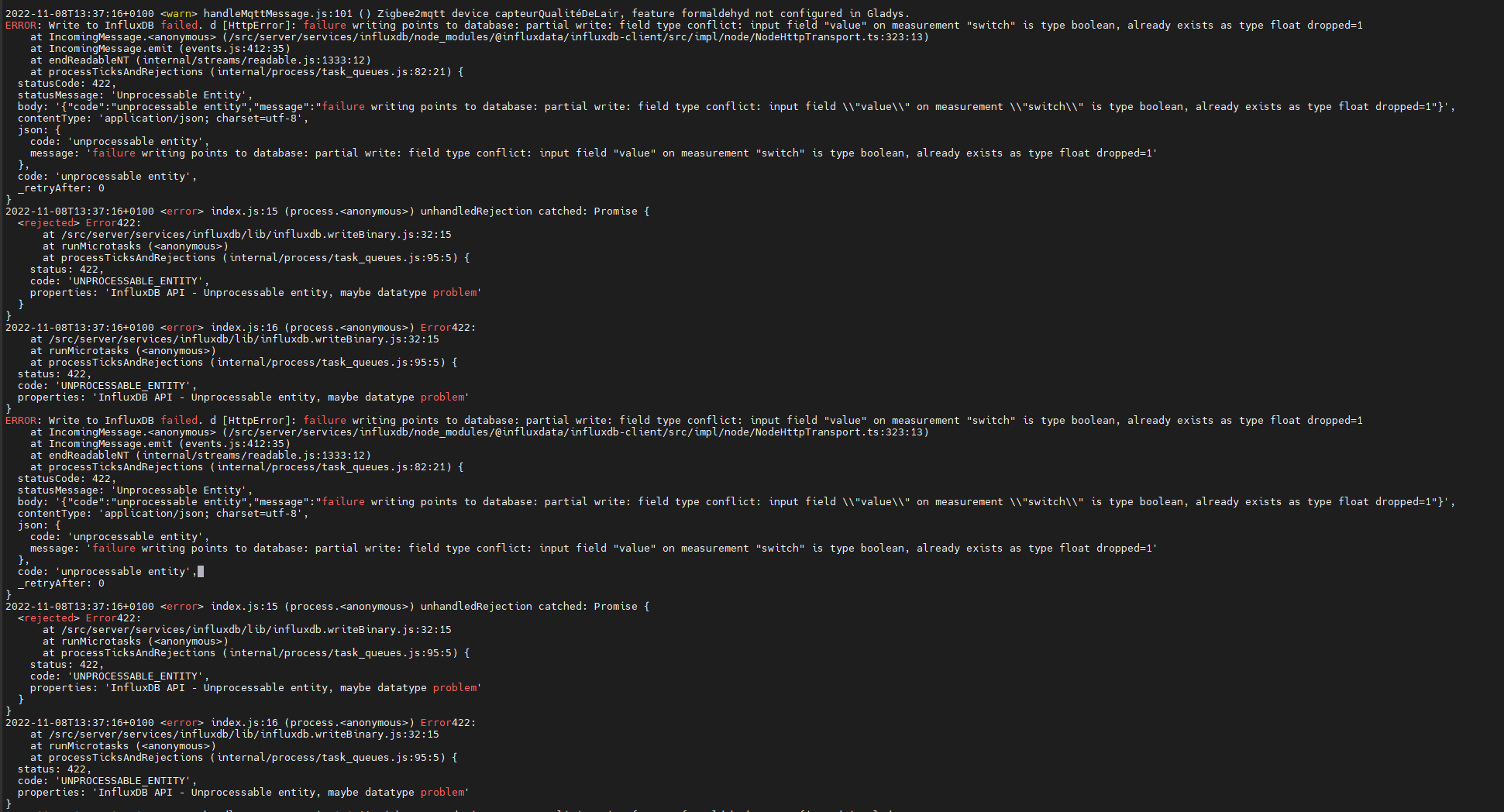
2022-11-08T13:37:16+0100 <warn> handleMqttMessage.js:101 () Zigbee2mqtt device capteurQualitéDeLair, feature formaldehyd not configured in Gladys.
ERROR: Write to InfluxDB failed. d [HttpError]: failure writing points to database: partial write: field type conflict: input field "value" on measurement "switch" is type boolean, already exists as type float dropped=1
at IncomingMessage.<anonymous> (/src/server/services/influxdb/node_modules/@influxdata/influxdb-client/src/impl/node/NodeHttpTransport.ts:323:13)
at IncomingMessage.emit (events.js:412:35)
at endReadableNT (internal/streams/readable.js:1333:12)
at processTicksAndRejections (internal/process/task_queues.js:82:21) {
statusCode: 422,
statusMessage: 'Unprocessable Entity',
body: '{"code":"unprocessable entity","message":"failure writing points to database: partial write: field type conflict: input field \\"value\\" on measurement \\"switch\\" is type boolean, already exists as type float dropped=1"}',
contentType: 'application/json; charset=utf-8',
json: {
code: 'unprocessable entity',
message: 'failure writing points to database: partial write: field type conflict: input field "value" on measurement "switch" is type boolean, already exists as type float dropped=1'
},
code: 'unprocessable entity',
_retryAfter: 0
}
2022-11-08T13:37:16+0100 <error> index.js:15 (process.<anonymous>) unhandledRejection catched: Promise {
<rejected> Error422:
at /src/server/services/influxdb/lib/influxdb.writeBinary.js:32:15
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:95:5) {
status: 422,
code: 'UNPROCESSABLE_ENTITY',
properties: 'InfluxDB API - Unprocessable entity, maybe datatype problem'
}
}
2022-11-08T13:37:16+0100 <error> index.js:16 (process.<anonymous>) Error422:
at /src/server/services/influxdb/lib/influxdb.writeBinary.js:32:15
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:95:5) {
status: 422,
code: 'UNPROCESSABLE_ENTITY',
properties: 'InfluxDB API - Unprocessable entity, maybe datatype problem'
}
ERROR: Write to InfluxDB failed. d [HttpError]: failure writing points to database: partial write: field type conflict: input field "value" on measurement "switch" is type boolean, already exists as type float dropped=1
at IncomingMessage.<anonymous> (/src/server/services/influxdb/node_modules/@influxdata/influxdb-client/src/impl/node/NodeHttpTransport.ts:323:13)
at IncomingMessage.emit (events.js:412:35)
at endReadableNT (internal/streams/readable.js:1333:12)
at processTicksAndRejections (internal/process/task_queues.js:82:21) {
statusCode: 422,
statusMessage: 'Unprocessable Entity',
body: '{"code":"unprocessable entity","message":"failure writing points to database: partial write: field type conflict: input field \\"value\\" on measurement \\"switch\\" is type boolean, already exists as type float dropped=1"}',
contentType: 'application/json; charset=utf-8',
json: {
code: 'unprocessable entity',
message: 'failure writing points to database: partial write: field type conflict: input field "value" on measurement "switch" is type boolean, already exists as type float dropped=1'
},
code: 'unprocessable entity',
_retryAfter: 0
}
2022-11-08T13:37:16+0100 <error> index.js:15 (process.<anonymous>) unhandledRejection catched: Promise {
<rejected> Error422:
at /src/server/services/influxdb/lib/influxdb.writeBinary.js:32:15
at runMicrotasks (<anonymous>)
at processTicksAndRejections (internal/process/task_queues.js:95:5) {
status: 422,
code: 'UNPROCESSABLE_ENTITY',
properties: 'InfluxDB API - Unprocessable entity, maybe datatype problem'
}
}
Procédure :
Lancer Gladys avec le service intégré Influxdb
Exécuter une scène à partir d’un bouton sans fil
Erreur
[EDIT]
On dirait un code HTTP 422 de retour de mon serveur InfluxDB, pour un type de données non accepté.
Testé comme demandé, et sur mon mini pc avec i5 cette fois.
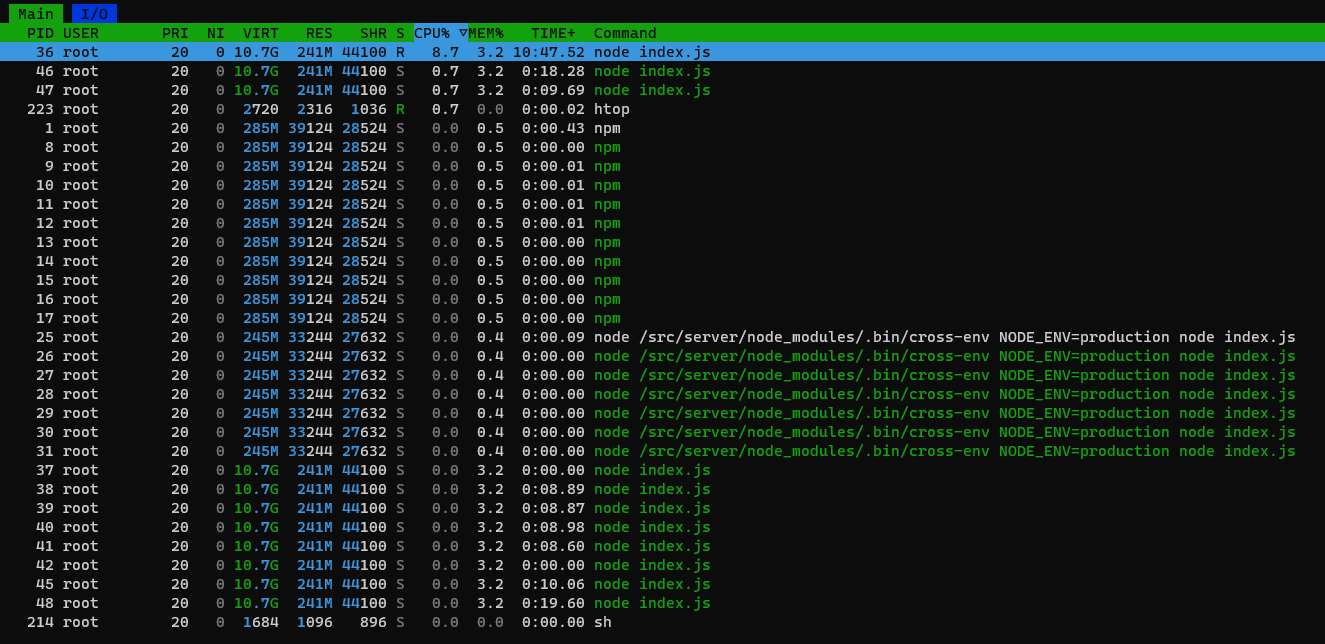
Même comportement, CPU du conteneur utilisé entre 6% et 30% lorsque Gladys sans service influx est à 0%.
Les logs montrent clairement que la haute activité des requêtes HTTP doit utiliser pas mal le CPU j’imagine.
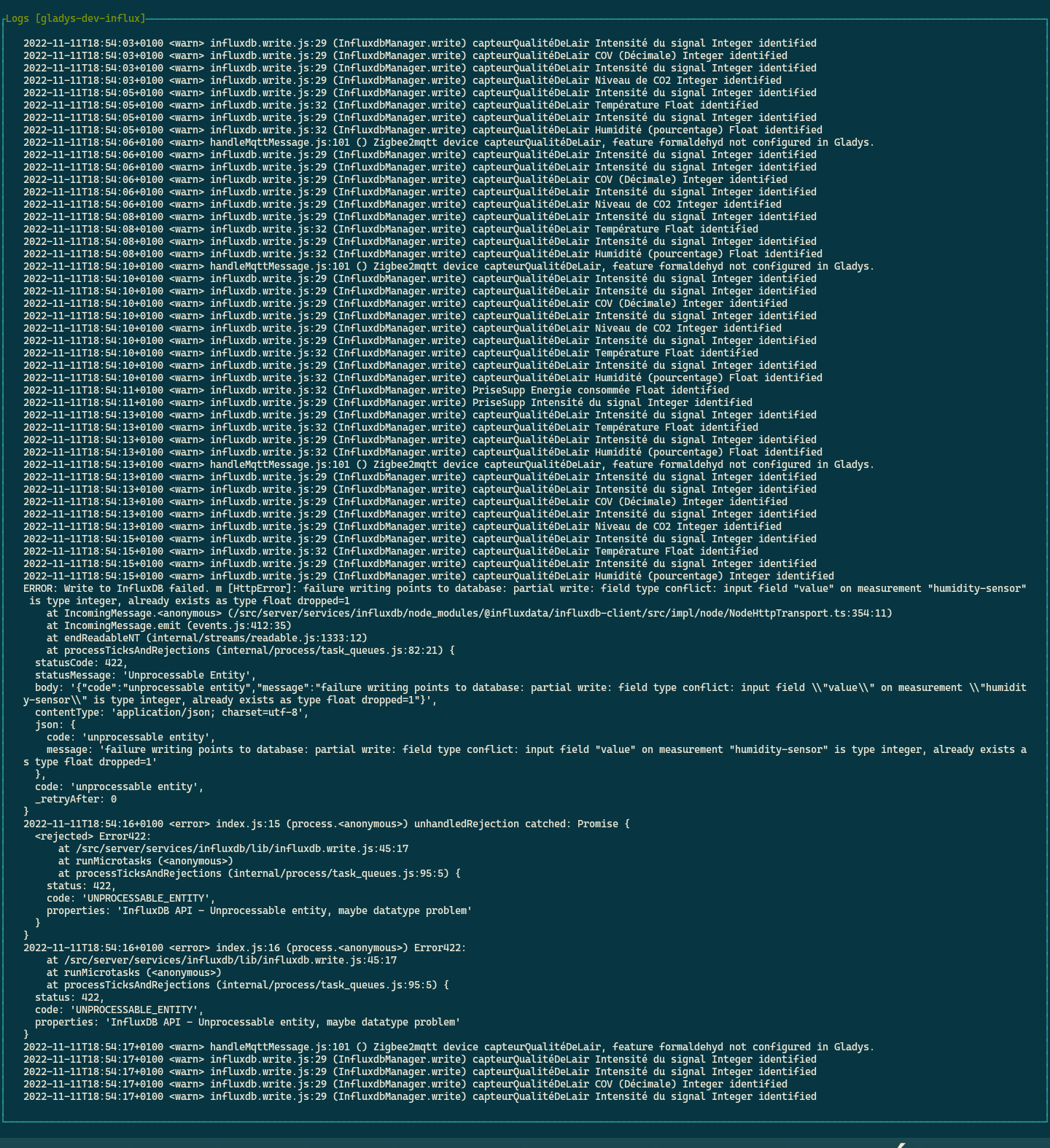
Mon capteur de CO2 et COV est très très verbeux (toutes les données sont mises à jour chaque seconde).
Enfin, il y a toujours une erreur sur un type de données, mais pas le même cette fois.
Une fois j’ai eu un cas similaire, une tache très consommatrice en ressources car elle devait traiter beaucoup de données.
En temporisant cette tache avec un « batch » on a totalement résolu ce problème.
Je vois les choses comme ça :
Collecte des événements à traiter pendant 10 sec
Envoie des 10 dernières secondes de données en une fois
Génial, si c’est déjà possible dans le client utilisé, j’espère que ça permettra de mieux optimiser les ressources. Je me dis que sur quelques équipements chez moi je constate une hausse du CPU, j’imagine même pas si quelqu’un d’autre avait le même capteur que moi, mais dans chaque pièces !
Sinon, j’ai aussi constaté une étrangeté. Un docker stats m’indique que ton conteneur consomme bien plus de RAM que Gladys.
+1 pour batcher les calls, c’est vraiment trop d’envoyer 1 par 1 à mon avis
Tu peux soit batcher temporellement (toutes les 10 secondes tu flush ta queue), soit batcher en nombre (tous les 100 éléments dans la queue tu flush), ou les deux.
J’ai pas mal utilisé la lib « bottleneck » pour faire ce genre de comportement sur d’autres projets. Ça peut se faire à la main aussi
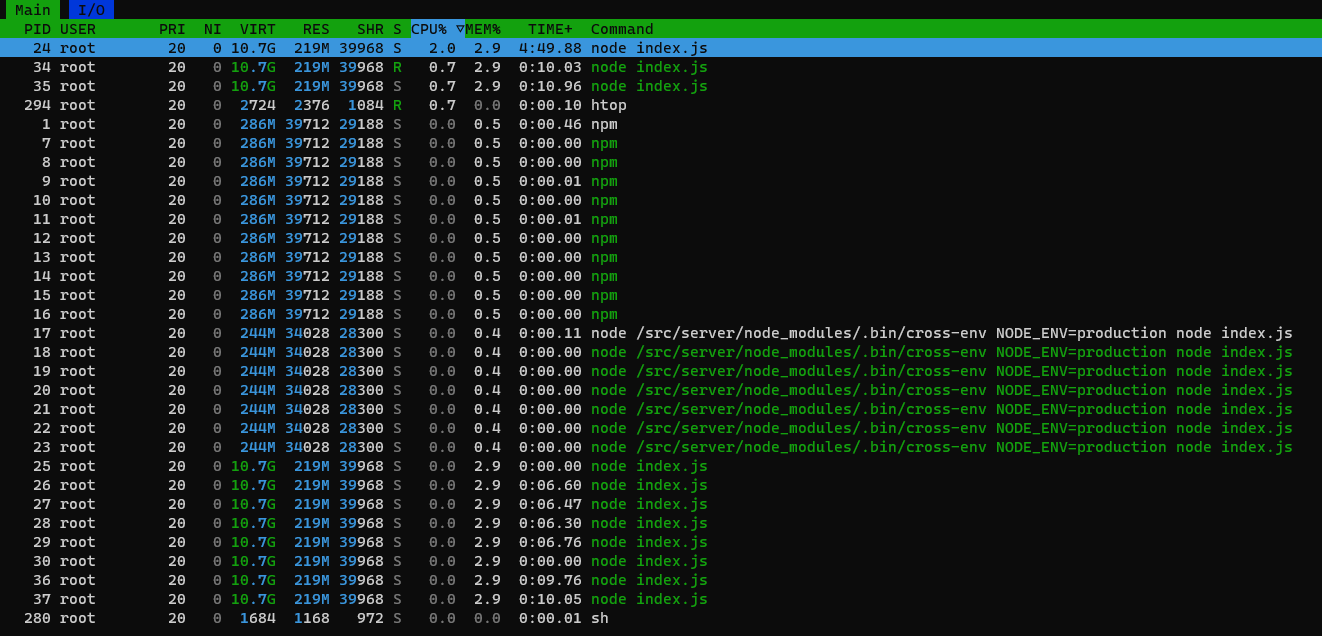
Je vois une énorme différence !
Le CPU du conteneur Gladys Influx dépasse à peine les 6% de CPU, généralement totalement synchro avec le conteneur original. Je n’arrive presque plus à me rendre compte d’une différence de consommation.
Pour moi le service est fonctionnel, tant que tu ajoutes les messages côté front-end type « configuration enregistrée » ou « erreur ».