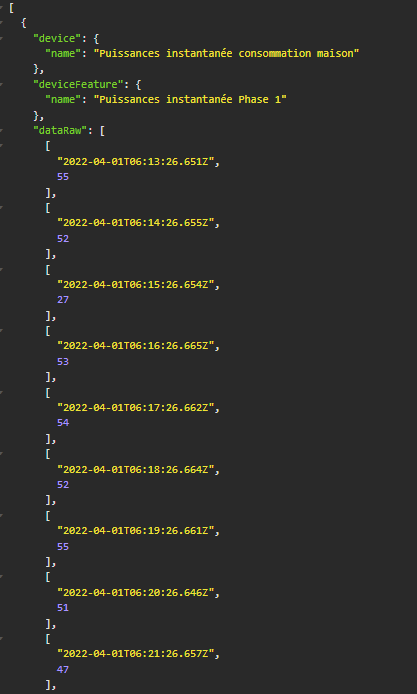
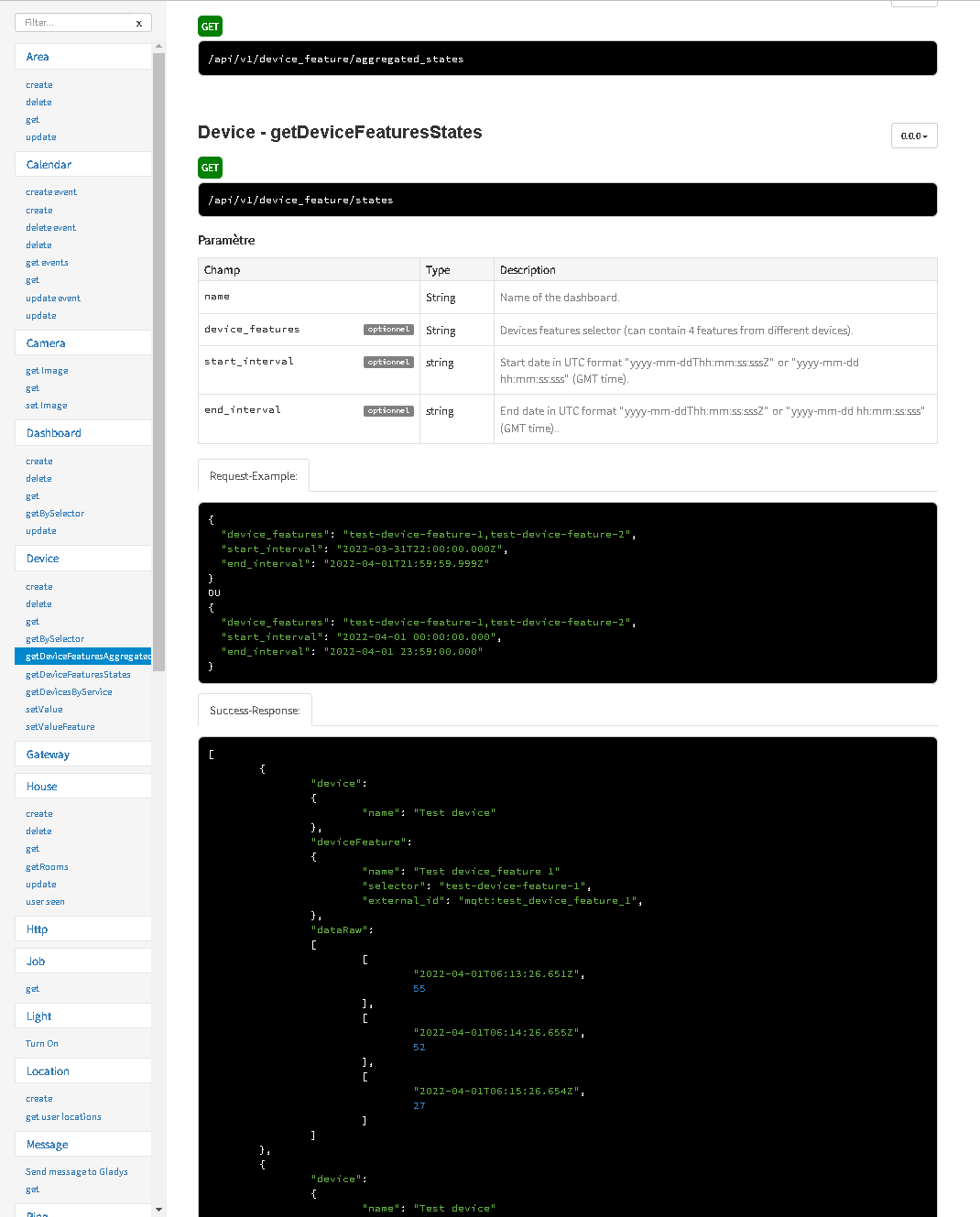
En fait j’ai plusieurs questions par rapport à ce qui a été développé.
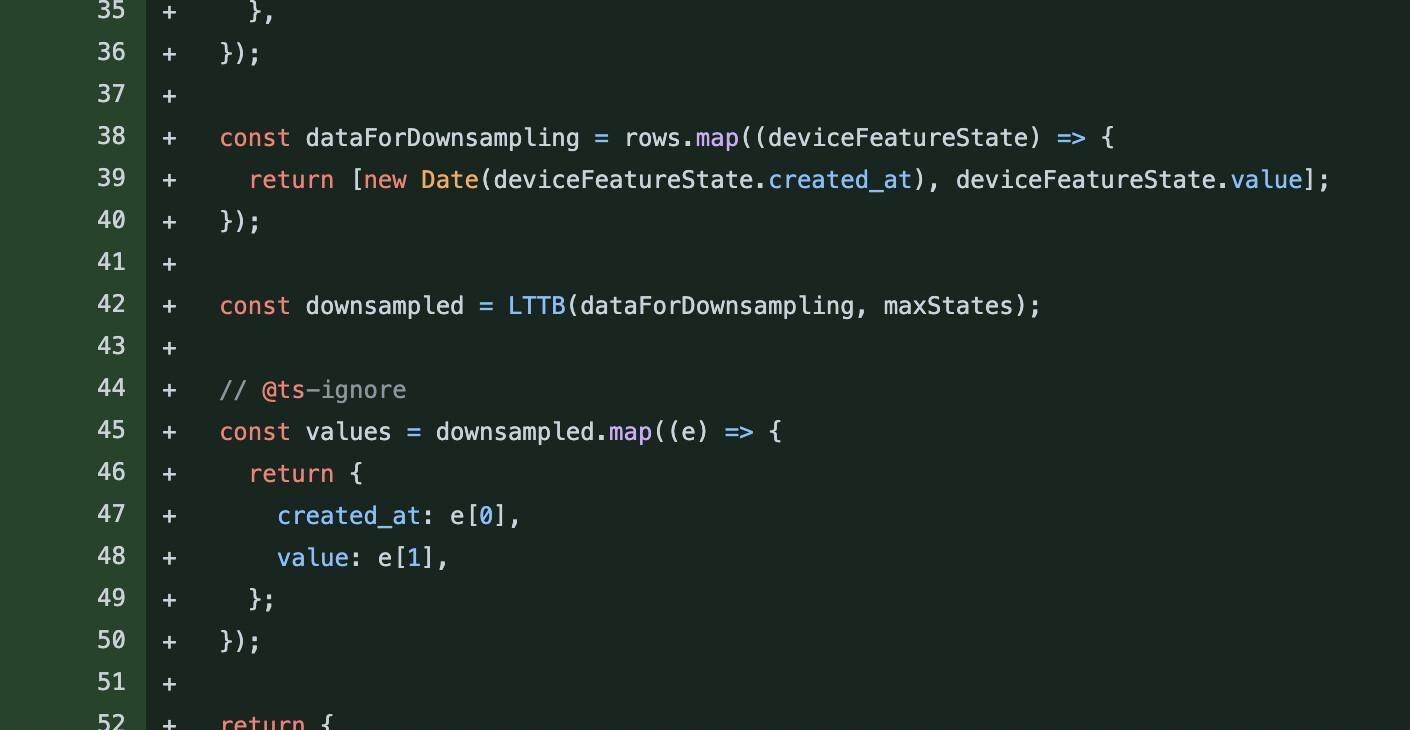
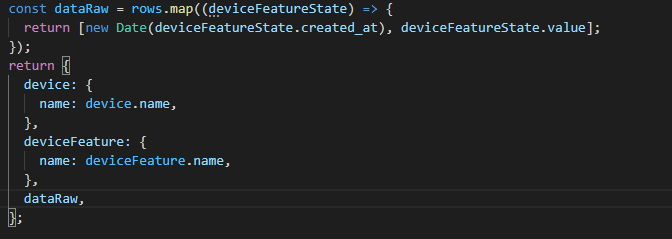
Là en l’état tu as copié coller le fonctionnement qui était fait sur la route “aggregated_states”, route qui avait un but précis : pouvoir afficher les graphiques de valeurs de capteurs de plusieurs capteurs.
Les paramètres et le format de cette route sont spécifique à ce besoin, et je suis pas sûr que ce soit le même besoin qu’ici, donc je ne pense pas forcément qu’il faille garder le même format d’API.
Je me demande si le besoin ici pour toi ce n’est pas plutôt une route de ce style là ( à débattre ) :
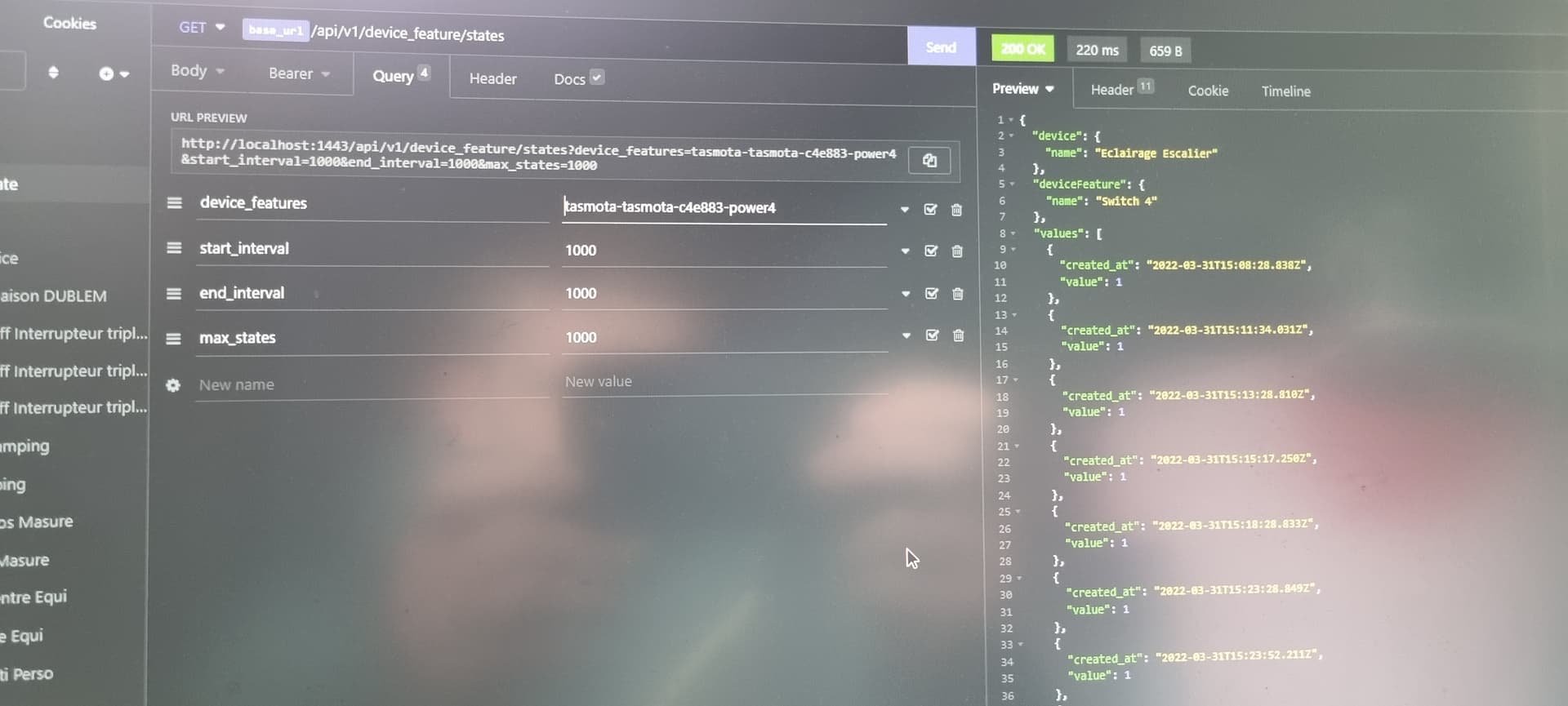
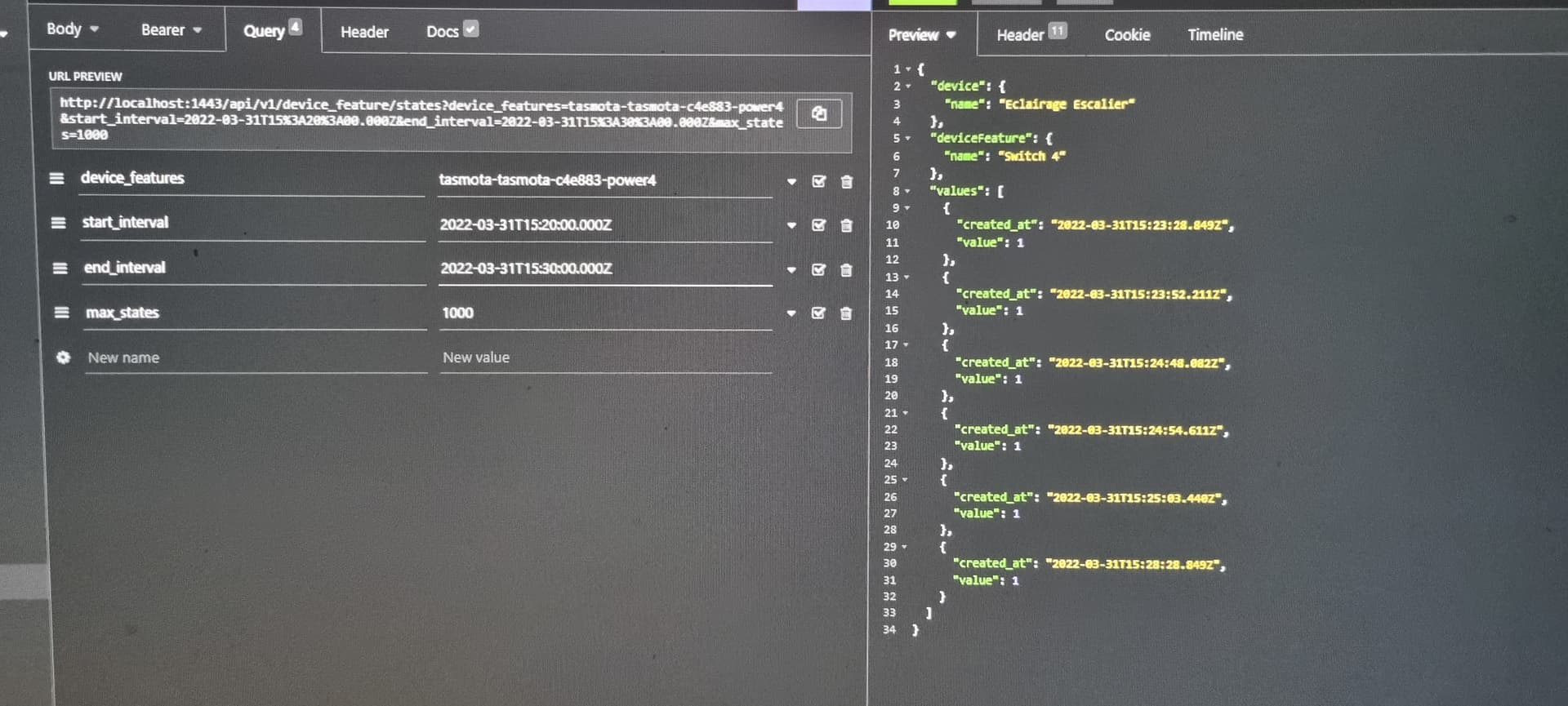
GET /api/v1/device_feature/:device_feature_selector/state
Avec en paramètres GET effectivement:
?from=DATE
&to=DATE
( J’ai changé start_interval / end_interval parce qu’on avait déjà ce from/to dans une autre route, /api/v1/user/:user_selector/location )
Ce qui permettrait éventuellement de mettre des paramètres optionnelles: ?take= et &skip pour ceux qui veulent utiliser cette route pour exporter des grandes quantités de données en chunk pour par exemple injecter ces données dans un Grafana, sans défoncer les performances de leur instance ^^
La réponse de cette route serait un tableau de state dans leur format en DB:
[
{
"id": "4ad21395-686b-41e5-988c-6e9201ba985a",
"value": 10,
"created_at": "2022-04-04 19:26:16.815 +00:00",
"updated_at": "2022-04-04 19:26:16.815 +00:00"
}
]
Je pense que c’est plus lisible, et plus adapté à ce qu’on veut faire là. Le fait de ne demander qu’un seul device_feature dans cette route permet de pouvoir gérer la pagination si besoin, pour quelqu’un qui veut faire des exports sans défoncer son instance Gladys (ce qui est sûrement ton cas j’imagine!!  )
)
Qu’en penses-tu ?
Je reviendrais ensuite sur le code, mais là le plus important pour moi c’est de se mettre d’accord sur la spec !