Je suis en train de travailler sur le développement de services permettant la compatibilité de Gladys 4 avec mon installation. Ayant déjà implémenté de la reconnaissance vocale dans la v3 avec Snips, j’envisage d’améliorer mon assistant Snips, et de développer un service qui se basera dessus.
J’ouvre donc ce topic afin que nous puissions discuter de ce service, savoir ce que vous voudriez voir apparaitre avec, les possibilités qu’un tel service apporte, et éventuellement collecter un certains nombre de phrases d’exemples qui servira à l’entrainement de l’assistant.
Salut
Je suis très intéressé par ce service
Je rechercherai :
un assistant évolutif (peu importe la phrase il comprendra le but).
un garde secret (tout en local).
Juste pas curiosité comment compte tu utilisés snips depuis son rachat par sonos on en parle ici ?
pour info rhasspy semble être le futur de l’open source de snips ^^.
Carrément ! Je l’ai installé et testé. Plutôt ravi du résultat. La communauté semble assez petite pour le moment mais les personnes ont l’air très actives.
Je ferai un petit topo avec capture d’écran dès que j’ai un moment.
Je découvre ton lien, moi je ne connaissais pas.
L’inconvénient c’est qu’il faut que tu l’associe à un Raspberry. Et entre l’achat du Pi et du matrix voice, autant partir directement sur un Respeaker.
Moi j’ai un Respeaker V2 6 mics. http://wiki.seeedstudio.com/ReSpeaker_Core_v2.0/
Hello @link39 as tu pu tester plus en profondeur Rhasspy ?
Ton avis m’intéresse, j’ai eu l’occasion de le tester un peu mais je ne suis pas trop rentré dans les détails encore
Oui testé et même approuvé ! J’utilise snowboy comme wake word avec le modèle universel “Jarvis” Français.
J’ai un respeaker 6mic avec une Pi pour le faire tourner.
Hello,
Rhasspy le speech2text marche bien.
Par contre vous avez testé le text2speech ? Y a t-il moyen d’avoir une voix correct sans pour autant passer par google voice ?
Hello @Biscotte,
Si tu veux tester Rhasspy en standalone et prévu pour du FR et que tu connais un peu docker, je t’ai déposé le fichier docker-compose ici.
Il y rhasspy + marytts (qui permet d’avoir d’autres voix). Les deux ont une interface web pour tester et les configurer. Je teste sur une vm debian sur ma machine windows pour utiliser le casque de mon pc.
Malheureusement je n’utilise pas Rhasspy avec gladys donc pas trop d’intérêt pour un tuto je pense.
Pour le moment il n’y a aucun lien entre rhasspy et gladys.
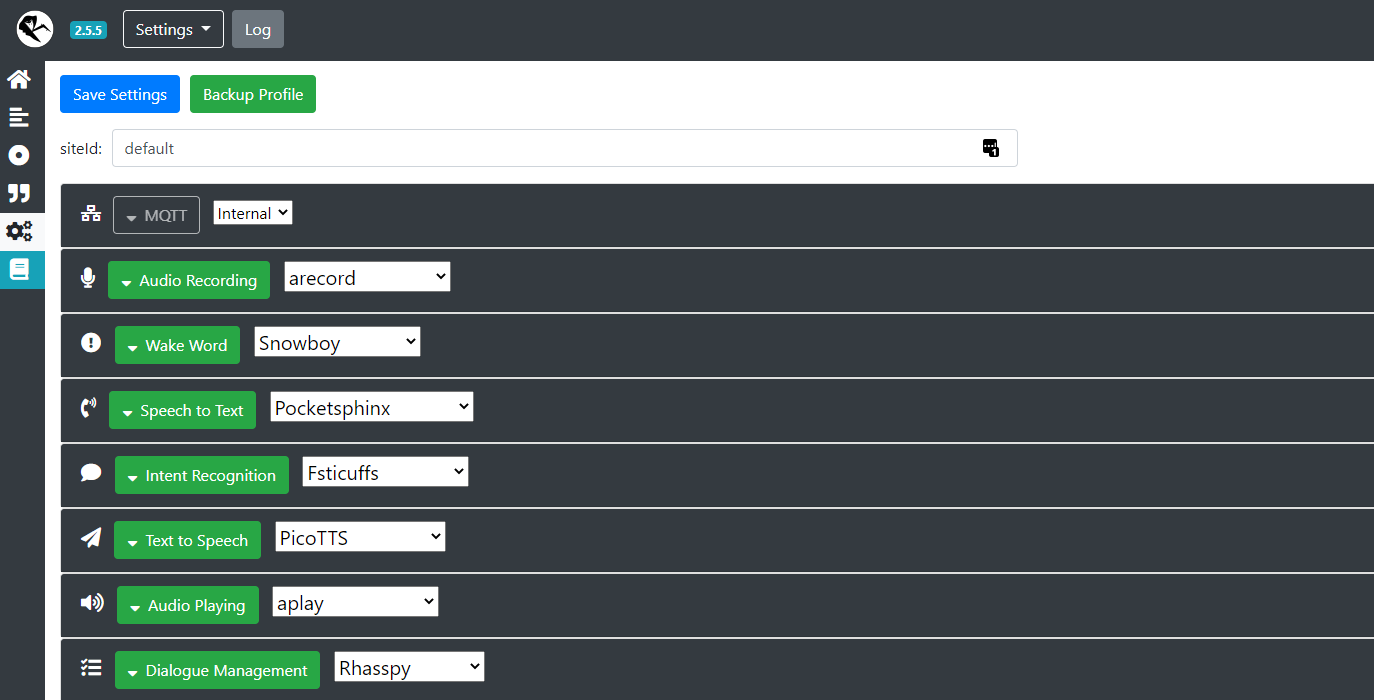
Pour rhasspy il suffit de déployer un container et ensuite d’aller sur l’interface Web pour le configurer. J’avais mis dans ce même thread la configuration que j’ai pour le wake Word, tts and co. Je peux vous faire une capture d’écran si vous voulez.
Pour avoir fais quelques tests, il est très facile de récupérer sur Gladys les évènements de rhasspy. En gros je récupère facilement toutes les demande sde l’utilisateur. Du coup cette partie pour moi sera facile à mettre en place.
La partie la plus compliqué sera la partie docker pour déployer rhasspy correctement sur toutes les machines.
Du coup j’ai une question concernant les messages.
Je vois que dans le code, il est nécessaire d’avoir un utilisateur pour que gladys puisse répondre à cet utilisateur quand on envoie un message.
Le soucis que j’ai c’est que je ne veux pas d’utilisateur car je sais pas qui a parlé dans le micro. Donc je peux pas associer d’ID. Surtout que la réponse se fera à l’oral. Donc je reçois bien le message de retour de Gladys mais il met une erreur car je défini l’id à null.
Peut-on envisager de modifier la route actuelle ou bien faut-il en créer une nouvelle plus spécifique à cette utilsiation ?