We had talked about creating a mapping table for this, right? @pierre-gilles you who noted everything, did we keep this possibility in mind? ![]()
Indeed, I think we had decided that the best approach was to handle this in the view with a specific type.
For example, in the case of the eco/freeze mode, it’s so specific that no generic button can display it (a select box would be so impractical for this ^^)
However, if we design a component that manages this type, then we can customize it, like a small widget with 4 buttons (I don’t know), but we can go wild with the design!
And most importantly, internationalization is super simple, it’s UI and we know how to internationalize the UI ![]()
Suggested folder structure:
- core
- server
- controllers
- models
- user
- user.create.js
- user.delete.js
- user.get.js
- user.login.js
- user.schemas.js
- index.js
- scenario
- services
- integrations
- zwave
- package.json
- sonos
- …
- config
- translations
- en.json
- fr.json
- tests
- index.js
- package.json
- package-lock.json
- client
- package.json
- package-lock.json
- PRIVACY.md
- README.md
- SECURITY.md
I have a few remarks ![]()
-
Why put the server and client in a « core » folder? I find that a bit weird

For me, the « core » is part of the server -
Same for the business logic in the « models » folder? That’s a bit weird ^^
-
Shouldn’t the folder containing the internal modules be named « service » instead? Given that’s how we refer to them in the UI ^^
-
And shouldn’t the translations folder be in the client folder? XD
I know nothing is set in stone and this is just a first draft, but it’s better to start on the right foot ![]()
I was thinking more of a fractal-type method, right?
Like this =>
- server
- controllers
- user.controller.js
----
- lib
- user
- user.create.js
- user.get.js
----
- index.js
----
- index.js
- models
- user.js
----
- routes
- user.routes.js
----
- middlewares
- utils
- services
- zwave
- sonos
----
- test
- server.js
- package.json
- package-lock.json
- client
- package.json
- package-lock.json
- PRIVACY.md
- README.md
- SECURITY.md
Ahaha good catch for all these remarks. I generally agree with everything and I like your structure proposal!
However:
For me, there will be translations on both the client and server side. Granted, almost everything will be on the client side, but on the server side, we still have translations to do (e.g., the title of a push notification to send, etc.).
Another remark, the « models » is still very vague since we don’t know yet which library we will use for the ORM. If we use Sequelize or Bookshelf, it will look a lot like the models of Sails.js. Problem: I looked and these two libraries seem to really want to do the coffee, and I don’t like that too much. I have the impression that it’s the same mess as sails. I would be more inclined to do pure Knex. And so the models would just be validation schemas with Joi.
Here is an updated structure with your remarks and mine.
Note: I added the « sentences » folder, which I organized by feature and by language, to avoid having something as heavy as the current 120km long files we have now ![]()
- server
- controllers
- user.controller.js
----
- lib
- user
- user.create.js
- user.get.js
----
- index.js
----
- index.js
- models
- user.js
----
- routes
- user.routes.js
----
- middlewares
- utils
- services
- zwave
- sonos
----
- test
- config
- translations
- en.json
- sentences
- say-hi.en.json
- say-hi.fr.json
- weather.en.json
- server.js
- package.json
- package-lock.json
- client
- package.json
- package-lock.json
- PRIVACY.md
- README.md
- SECURITY.md
Aaaahhhh good catch! I hadn’t thought of that!
In that case, yes, there is an interest in having it on the server side as well!
Indeed, it will always be better ^^
I don’t know if there will be a lot of things to share between the server and client, but if so, there could be a share folder at the same level as server and client where there would be translations, helpers, shared config files, constants, or others. At my company during my first internship, that’s what we did in Java ^^
This will prevent the client from looking for translations in the server folder, just by principle, it’s weird ![]()
I agree, but I want to see with use if we really have these cases ![]() We can start development without it, and as soon as it happens, we create it.
We can start development without it, and as soon as it happens, we create it.
You mean integrating specific APIs for these devices into the core?
If that’s the case, we discussed it and I think we decided to take Apple as an example with their specific functions dedicated to certain types of devices to better manage them. ![]()
Your repo is pretty good!
@piznel: Great find this repo! I really like it ![]()
It’s true that device abstraction was a goal of v3, but I don’t think it went far enough.
Actually, the mistake in v3 is that I wanted to make everything generic without any bias ![]() (I said this to the guys during the developer meetup) and thus without implementing device categories in the core code.
(I said this to the guys during the developer meetup) and thus without implementing device categories in the core code.
Until now, we had this on a much smaller scale with a virtual module in the tests (a module that did a bit of everything by just returning Promise.resolve everywhere (here))
I agree that for v4, it would be best to be able to do as much testing as possible (both automated and local) with virtual device categories, and that modules extend these core definitions to implement certain functions in the « real » world.
Then, in terms of HTTP API, we need to decide whether to keep a « generic » API for devices or whether to split by categories:
POST /devicefeature/:id/exec
or
POST /light/:id/on
POST /light/:id/off
POST /light/:id/luminosity/100
We read Apple’s documentation at the developer meetup and their class definitions are interesting =>
Edit: Here are the categories that Apple manages:
- Door locks
- Fans
- Garage door openers
- Lights
- Outlets
- Thermostats
This raises a very good question that hasn’t been addressed here yet ![]()
If we want to enforce strong typing to maintain consistency in the objects we send around:
- TypeScript or not TypeScript?
I have mixed feelings about this. I currently work with TypeScript both in my full-time job and as a freelancer. I love the flow and rigor it brings (autocompletion, code that screams at you when you do something wrong, it catches an incalculable number of bugs). I’m pretty fond of working with it right now.
But:
- it’s still another language
- it adds a compilation step
- I’m afraid of the hype, that it will fade away, that a more performant/cleaner solution will come along, and that in 1-2 years we’ll have to rewrite everything from scratch because nobody uses TypeScript anymore ^^
- it adds a barrier to entry for developers who want to join the project. It’s not just JS anymore, it’s an entirely different language they need to know.
Let me know your thoughts on this, I’m interested ![]()
Small update on my various explorations related to different ORMs
https://twitter.com/pierregillesl/status/1092279982674501632
Knex: It’s cool, but it’s quite minimalist, it just does query building
Knex + Bookshelf: The power of Knex, but with an ORM for model validation. After that, the function naming and the flow are a bit weird and not so modern (it smells like an old library that has modernized little by little, not everything is always logical). The bookshelf project seems to be maintained but not with sustained development.
To create a model:
const User = bookshelf.Model.extend({
tableName: 'users'
});
To insert:
const newUser = await User.forge({name: 'Tony'}).save();
console.log(newUser.toJSON());
I’m not a fan of the naming and the flow. Why forge? Why .save()? Why toJSON()?
It’s a bit heavy I find.
Number of downloads: 33k/week.
Sequelize: I had preconceived notions about Sequelize, and well I tested it, and it’s actually amazing ![]() . The migration part is very well managed, and it’s much less of a gas plant than I imagined.
. The migration part is very well managed, and it’s much less of a gas plant than I imagined.
You define your models like this:
const Contact = sequelize.define('Contact', {
id: {
type: DataTypes.UUID,
primaryKey: true,
defaultValue: DataTypes.UUIDV4,
},
firstName: DataTypes.STRING,
lastName: DataTypes.STRING,
phone: DataTypes.STRING,
email: DataTypes.STRING
}, {});
And then it’s super simple:
const newContact = await db.Contact.create({
firstName: 'Scooby',
lastName: 'Doo',
phone: '444-555-6666',
email: 'scooby.doo@misterymachine.com'
});
They also have a CLI that rocks and allows you to execute migrations/rollbacks, it’s very well done.
node_modules/.bin/sequelize db:migrate:undo
node_modules/.bin/sequelize db:migrate
In terms of maintenance and number of downloads, we’re talking about 283k downloads/week, so it’s quite popular.
And in the end, it’s far from being sails in terms of « locking », you can do what you want in fact. It’s really free.
Finally after testing, it’s my big favorite ![]() As they say, you have to test to form an opinion!
As they say, you have to test to form an opinion!
Yes and +1 for index management ![]()
Personally, I’ve used Sequelize for a project. And it’s really great. Already in terms of security it’s nice because you can really define precise models (isEmail, number, regex, …).
And in use it’s simplicity itself!! Conditions easily usable, modification, uses everything is great. When you use await/async it becomes super powerful ![]()
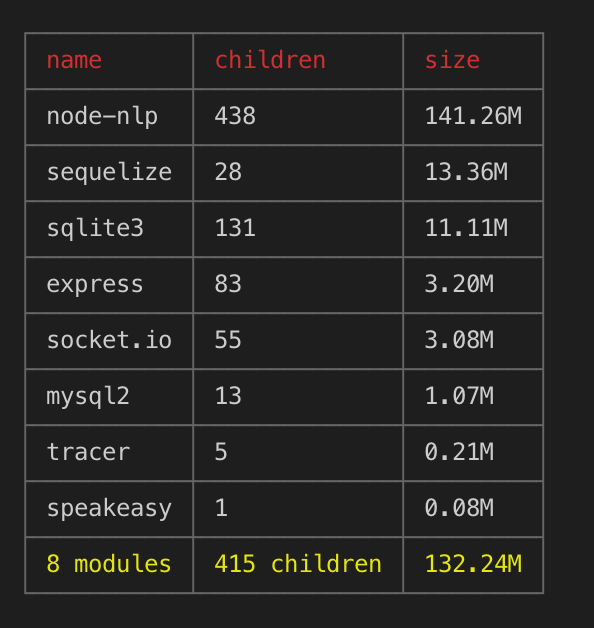
In investigating, just their module contains:
- The docs
- Screenshots
- Useless dist files
By removing all that, we go from a 60MB lib to 9MB!
I think I’m going to make them a PR ![]()
Hop PR pushed =>
I started a « playground » repo for Gladys 4, which will probably stay in the development repo until it’s merged into the main repo.
https://github.com/GladysAssistant/gladys-4-playground
I did the boring work this morning, which was to set up a very solid and strict ESLint configuration.
To make sure it’s super strict but realistic, I tried it on the Gladys Gateway configuration. I extended the basic Airbnb configuration by adding my own rules.
On the Gateway, it found 2,500 errors (even though I already had a pretty strict configuration), I’m pretty happy with the result ![]()
I pushed this to the playground repo
Hello everyone!
Well, I haven’t been idle today, I’ve created the entire « backend » project ![]() It’s a first POC, nothing final. The goal is to see if the folder structure/code structure pleases us. The coding style too.
It’s a first POC, nothing final. The goal is to see if the folder structure/code structure pleases us. The coding style too.
Everything is available here →
https://github.com/GladysAssistant/gladys-4-playground/tree/master/server
I enabled ESlint in hyper strict mode as I said earlier.
I enabled APIDoc + JSDoc + an ESlint plugin that validates the comments and refuses code without comments, and checks that the code and comments are in sync (and that’s magical!)
Demo:
Let me know what you think.
I’m not yet a fan of everything I must admit, I have the impression that the project is a bit « draft » for now…
It must be understandable for anyone who comes to the project!
I just set up tests + coverage on TravisCI: