Déjà ça commence mal ^^
Cela dit je trouve pas que ça soit brouillon perso 
Ok je fix 
Je vais utiliser ce package pour faire du cross-platform la dessus:
J’ai fixé le truc juste en mettant ‘SET’ devant le NODE_ENV ^^
Mais je sais pas si après ça va fonctionné sur les autres plateformes
Edit: rajoute un script de start et npm i aussi au package root ça serais pratique
Non, c’est bien pour ça qu’il y a un module qui gère différentes plateformes 
J’ai pushé, ça devrait fixer chez toi!
Btw, quand c’est devDependencies c’est pas trop grave d’installer des petites dépendances pour ce genre de chose, faudra juste s’assurer que ces dépendances ne soient pas dans le build de prod sinon ça va vite être lourd
Effectivement c’est beaucoup mieux d’un coup ^^
Je sais pas, je me tâte à mettre le dossier « controllers » et « middlewares » dans un dossier « api »… Après enfouir dans des sous dossiers c’est pas toujours la meilleure idée…
Yes! Après je configurerais le package root quand il y a aura le front.
Il faut que tout soit transparent pour le dev et l’utilisateur.
En dev ça lancera le serveur hot reload du front et du back
En prod ça lancera juste le server qui exposera la SPA buildée
Oui effectivement c’est pas forcément la meilleur idée, c’est comme ça qu’on se perd vite dans les montagnes de sous dossier ^^
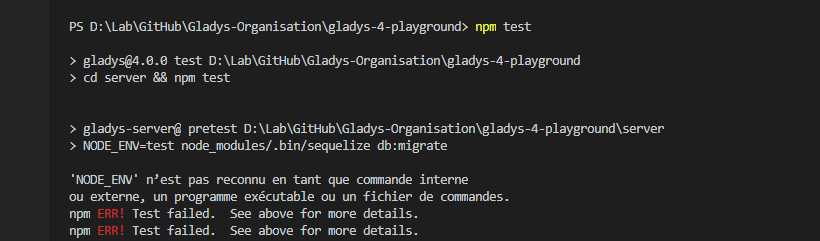
Petite question, tu as passé le test eslint avec succès je suppose ?
Oui pourquoi ça marche pas chez toi?
ça passe pourtant en local + sur Travis!
Tiens du coup ton avis sur le repo peut être intéressant! Pour toi ça fait clean?
Nope, je me prend 416 erreurs à la figure !
Mais je soupçonne VSCode de ne pas prendre la bonne config eslint… alors qu’il me semble qu’il prend automatiquement la config du projet
Je dois rater un truc… c’est bien la première fois qu’il me fais ça…
Ah c’est sûr ça doit être ça! Enquête sur ta conf de VScode…
Non mais c’est bon j’ai trouvé, merci windows
C’est une histoire de saut de ligne, windows utilise le type CRLF par défaut alors que MAC et Linux seulement un LF, du coup comme les fichiers ont tous été créé sur MAC mon VsCode interprète mal les règles eslint et me sort des erreurs de saut de lignes partout 
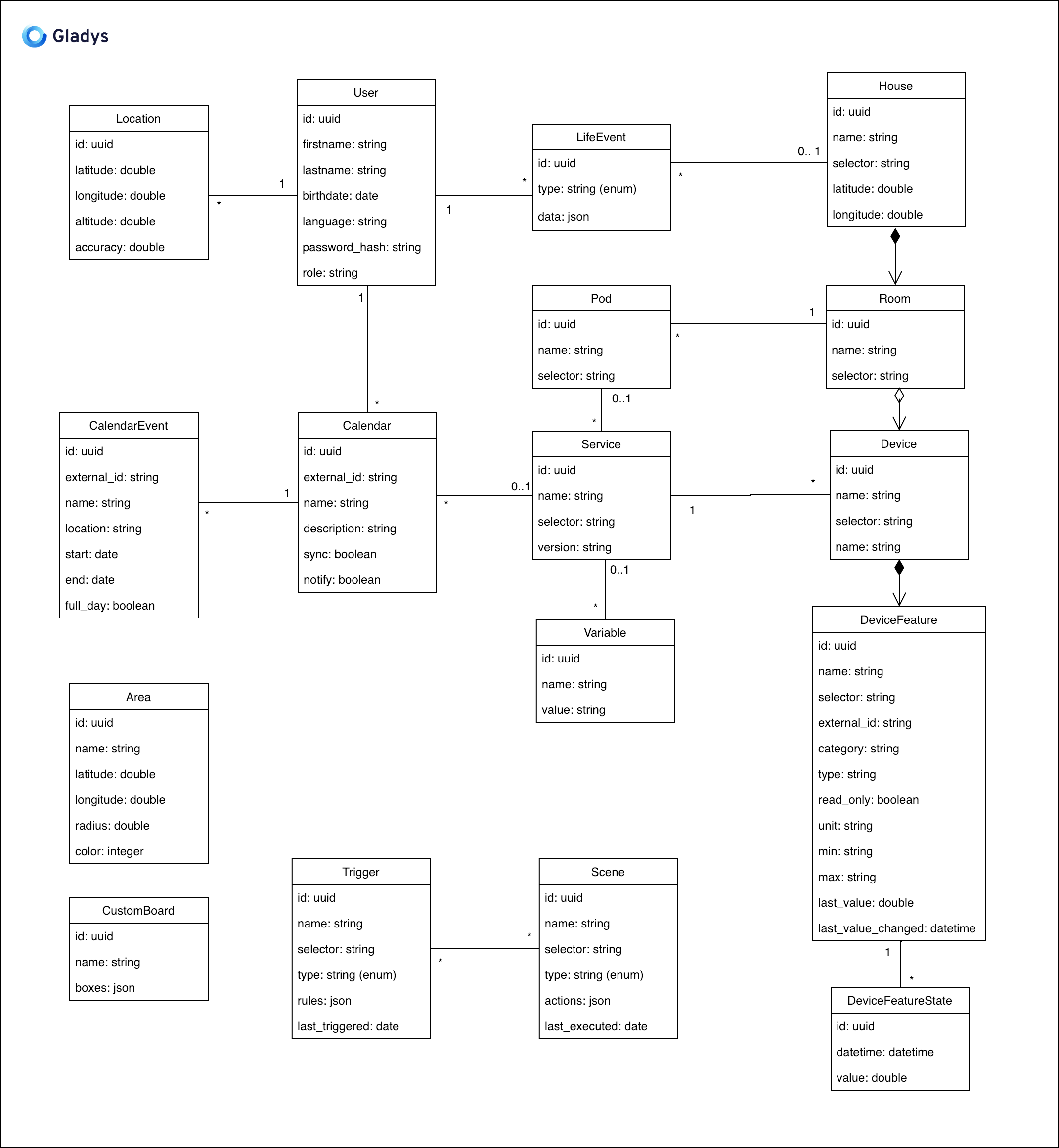
Salut à tous!
Je viens de finir une première version de la modélisation de base de donnée ![]()
Dites moi ce que vous en pensez, il y a peut-être des choses à changer/des oublis. Dites moi!
Je t’ai répondu à ta PR, c’est pas ce qu’on veut de désactiver la règle! ![]() ça va être le bordel sinon. Il faut que tu configures ton IDE pour qu’il gère le LF sans problème (c’est dans les paramètres de VSCode)
ça va être le bordel sinon. Il faut que tu configures ton IDE pour qu’il gère le LF sans problème (c’est dans les paramètres de VSCode) ![]()
Autre nouveautés, j’ai défini la structure des package.json des services internes dans Gladys 4.
Voilà un exemple:
{
"name": "gladys-example",
"main": "index.js",
"os": [
"darwin",
"linux",
"win32"
],
"cpu": [
"x64",
"arm",
"arm64"
],
"scripts": {},
"dependencies": {
"axios": "^0.18.0"
}
}
Le module doit désormais spécifier 2 attributs supplémentaires: “os” et “cpu”, afin d’indiquer les plateformes sur lequel marche le service.
Quand on fera un build de Gladys pour une plateforme, NPM fera les vérifications nécessaires si il est possible ou pas d’installer le service.
Ces règles:
Sont vérifiés par une batterie de tests afin qu’on soit certain que tous les modules soient stricts à ce propos.
@MathieuA Bon j’ai changé un peut l’architecture et la façon d’instancier la librairie Gladys et les dépendances.
Les controllers ressemblent à ça:
Je trouve ça plus clair, et avoir tous les controllers d’une entités dans un même fichier je vois pas le problème, c’est tellement fin les controllers… Et je préfère faire de l’injection de dépendances plutôt que du require pour ici.
Ensuite, autre changement, la lib Gladys doit aussi être instanciée, afin qu’on puisse gérer les “states” plus facilement.
Je m’explique, avant j’avais l’habitude faire des fichiers “shared.js” pour stocker des états partagé entre plusieurs fichiers. ça faisait le boulot, mais bon c’est pas super, en gros je me servais de require() comme fournisseur de singleton ^^
Proposition: De la même manière que les modules, chaque service est une fonction qui renvoie des fonctions (en gros, c’est comme une classe qu’il faut instancier)
Donc pour lancer Gladys, on fait:
https://github.com/GladysAssistant/gladys-4-playground/blob/master/server/index.js
Je pense qu’on aura un lifecycle de l’app plus clair du coup et un management des états plus propre.
PS: j’ai mis “controllers” et “middleware” et “routes.js” dans un dossier “api”, je trouve ça plus clair
Si quelqu’un a des retours, je suis preneur 
Ahah je me doutais que t’allais me repondre ça ! ^^
Sauf que ça va être le bordel si tu désactive pas cette règle plutôt ![]()
Parce que du coup j’ai cherché et on peut pas configurer VSCode pour qu’il prene en compte automatiquement le type saut de ligne. La seule configuration qu’on peut faire c’est de spécifier le saut de ligne quand on crée un nouveau fichier. Sauf que pour les fichier existant le seul moyen c’est de modifier manuellement mais ça entraîne de fauses modifs pour Git qu’il faudrait que je commit… mais c’est un peu con.
D’autant plus que je suis pas le seul a dev sur Windows donc il y aura forcément des conflits avec d’autres. Et quand eux ou moi vont te faire des PR pour des nouveaux fichiers avec des saut de ligne Windows ça va entraîné des erreurs certainement lors des tests auto ou même que quand ça sera chez toi !
Et honnêtement avec le peu de fichiers qu’il y a dans le projet j’ai déjà plus de 400 erreur lors du test chez moi donc quand le dev sera plus avancé j’abandonnerais l’idée de lancer le test ![]()
J’ai cherché si on pouvais faire quelque chose avec la conf eslint mais rien n’est prévu apparemment, c’est soit l’un soit l’autre ![]()
Donc je me suis dit que le mieux était de désactiver cette règle, c’est pas comme si je désactivais la verif des coms ![]()
Heyy pas de panique on va trouver une solution ^^
C’est normal d’être consistent à travers le projet non? Tous les projets open-source sérieux font ça, si au bout de 1 jour d’avoir mis un ESlint strict on baisse déjà les bras on va pas aller loin.
(je dis ça parce que clairement cette règle c’est la règle la moins dur à suivre, derrière il y a d’autres règles beaucoup plus stricts sur le coding style)
J’ai cherché sur internet, et c’est possible de créer un fichier .editorconfig dans le repo Git, qui va donner une indication à ton Vscode que ce projet a choisi “LF” comme style de fin de ligne. C’est un format de fichier cross-éditeur donc ça aidera aussi les devs sous Atom ou autre IDE.
Exemple sur un projet open-source:
Est-ce que tu peux tester ça? Si c’est ça je mettrais ce fichier sur le git
Si c’est pas ça j’ai trouvé des dizaines de sujets sur la question, c’est un problème basique on va trouver
Autre problème, c’est peut-être ton Git qui est configuré pour remplacer tous les LF par des CRLF lors du pull.
Je suis totalement d’accord ^^
Mais après avoir cherché pendant heure hier ça m’a saoulé ![]()
Je l’ai pas eu celui la ! Et ça fonctionne ! J’étais tombé sur une histoire de fichier .gitattributs aussi mais ça avait pas fonctionné. C’est un peu mystique car VSCode m’affiche bien le type de ligne Windows en bas mais j’ai plus d’erreur ![]()
Ah j’ai tenté ça aussi mais ça n’a rien donné ![]()
Mais pour le coup le fichier editorconfig fonctionne impec !
Arf j’ai parlé trop vite 
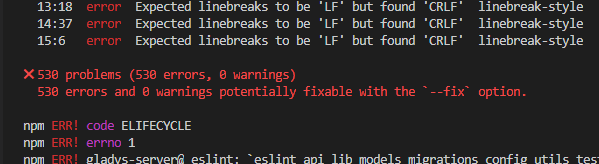
Ça ne change rien…
C’est normal!
En gros ce qui s’est passé là, c’est que quand tu as cloné le projet, soit Vscode, soit git a pensé que tu voulais convertir le projet en CRLF, et à converti tous les fichiers de LF a CRLF (c’est pas ce qu’on veut)
Donc ce que je ferais:
1/ il faut qu’on ajoute ce fameux fichier au git
2/ tu reclone le git, et on regarde si c’est bon ou pas